Claude Code Security: A Reasoned Take on What It Means for AppSec
- Chris Hughes from Resilient Cyber <resilientcyber@substack.com>
- Hidden Recipient <hidden@emailshot.io>
Claude Code Security: A Reasoned Take on What It Means for AppSecLLMs are changing vulnerability discovery, but the complexity of application security demands more than reasoning aloneThis week the AppSec world is still buzzing from Anthropic’s launch of Claude Code Security, a native capability built into Claude Code that scans codebases for vulnerabilities and suggests targeted patches using reasoning-based analysis rather than traditional rule matching. Within hours of the announcement, cybersecurity stocks tumbled. CrowdStrike dropped nearly 8%, Okta fell almost 10%, and JFrog shed roughly 25%. The Global X Cybersecurity ETF extended its year-to-date losses to nearly 16%.
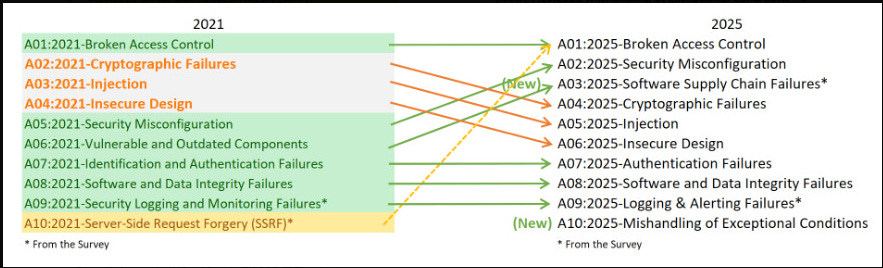
As I wrote in my initial reaction, the market is pricing in the directional signal: frontier AI labs are moving from only writing code to also policing it. But markets often trade the direction of travel, not the fine print, and the fine print here matters enormously. Claude Code Security is a meaningful step forward. It is not, however, a panacea. And the gap between a compelling research preview and a production-grade AppSec program is wider than most of the excited commentary acknowledges.  Interested in sponsoring an issue of Resilient Cyber? This includes reaching over 31,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives Reach out below! What Claude Code Security Actually DoesRather than scanning for known patterns the way legacy SAST tools do, Claude Code Security reads and reasons about code contextually, understanding how components interact, tracing data flows, and catching complex vulnerabilities that rule-based approaches miss. Every finding goes through a multi-stage verification process where Claude re-examines each result, attempting to prove or disprove its own conclusions before surfacing them to analysts. Findings are assigned severity and confidence ratings, and nothing gets applied without human approval. The results backing this up are genuinely impressive. Using Claude Opus 4.6, Anthropic’s team found over 500 previously unknown high-severity vulnerabilities in production open-source codebases, bugs that had gone undetected for decades despite years of expert review and fuzzing. These included subtle heap buffer overflows and complex logic flaws that traditional scanners consistently miss. This matters because the vulnerability classes that actually get exploited in the wild are overwhelmingly the ones traditional SAST tools struggle with. Look at OWASP’s 2025 Top 10 update: Broken Access Control has been sitting at the top of the list for half a decade. That’s a business logic and authorization problem, not a pattern-matching problem. If LLM-based reasoning can make a real dent in those categories, it’s a significant advancement for defenders. This is a topic I discussed in my prior article “The OWASP Top 10 Gets Modernized”.
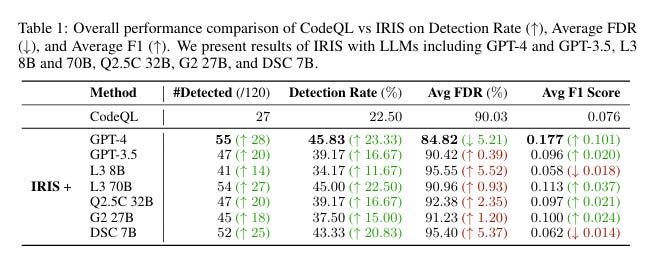
Where LLMs Genuinely HelpI want to give credit where it’s due, as the research supporting LLM-augmented code analysis is substantial and growing. Multiple studies have demonstrated that coupling LLMs with traditional SAST tools can dramatically improve signal quality. Research on LLM-Driven SAST approaches has shown false positive reductions in the 91–98% range. Other work, including the IRIS neuro-symbolic approach from ICLR and Datadog’s Bits AI integration, confirms that the hybrid pattern of using SAST for initial detection and LLMs for contextual validation is the most promising direction.
This is genuinely transformative for an industry where false positive rates have been the primary driver of developer distrust and tool abandonment. Anyone who has worked in AppSec knows the painful reality: teams drowning in findings, developers ignoring scanners because 60–80% of what gets flagged isn’t exploitable, and security backlogs growing faster than they can be triaged. These are topics I have addressed many times, in articles such as “Security Throwing Toil Over the Fence”.
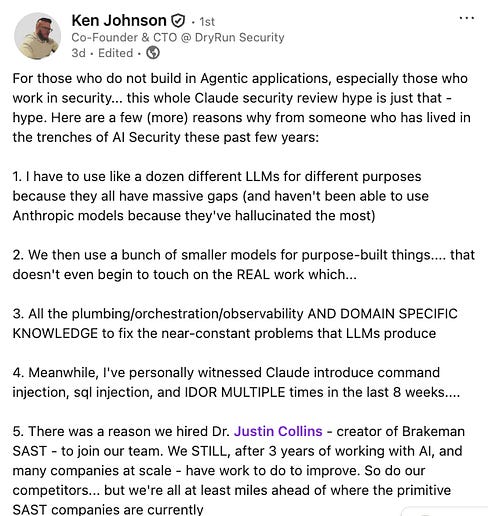
If LLMs can be the intelligent triage layer that converts a mountain of alerts into a handful of verified, actionable findings, that alone changes the economics of AppSec. It can also help us get away from developers considering security a “soul withering chore”. The leading research consensus is clear: the winning approach isn’t LLMs alone or SAST alone, it’s coupling them together so that each compensates for the other’s weaknesses. The Problems That RemainBut here’s where the nuance matters, and where much of the hype-driven commentary misses the mark. LLMs are probabilistic systems. They hallucinate. They’re inconsistent across runs. They consume significant tokens and compute. And when it comes to generating secure code, the data is sobering. Some of these points were made by DryRun Security’s Cofounder & CTO, Ken Johnson:
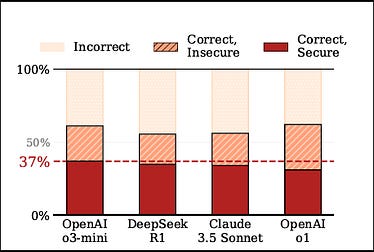
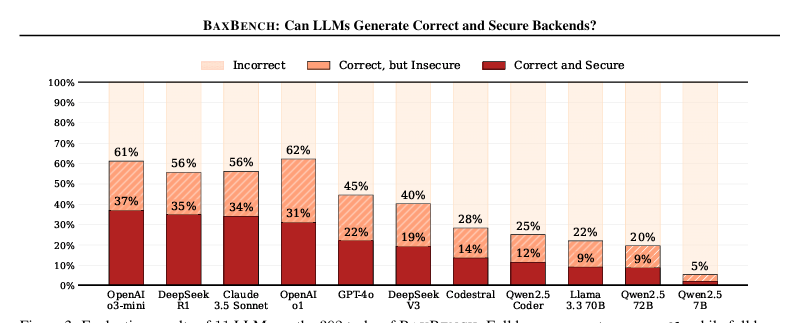
BaxBench, the ETH Zurich benchmark evaluating LLMs on backend code generation, found that 62% of solutions generated by even the best models are either functionally incorrect or contain security vulnerabilities. Of the code that works correctly, roughly half can still be exploited.
I covered BaxBench and similar findings in my article “Fast and Flawed,” where I dug into Veracode’s research showing that nearly half of all LLM outputs were insecure, and that security performance remained flat despite larger and newer models. Bigger doesn’t mean more secure.
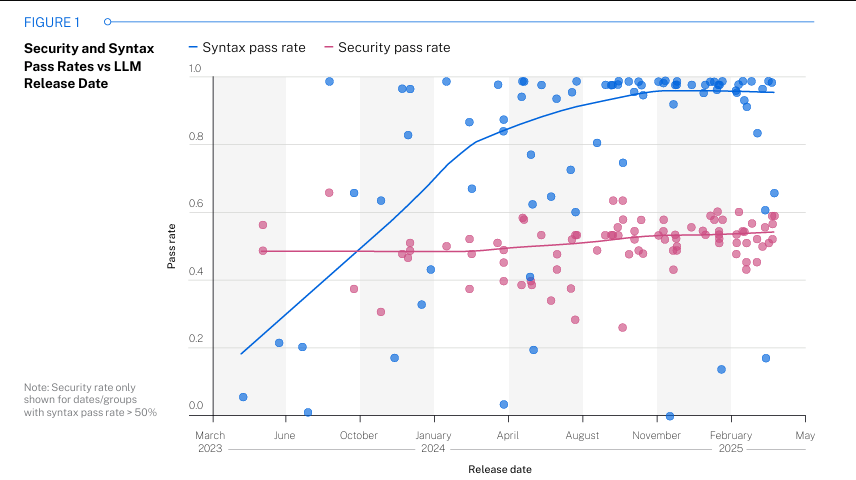
Similar research such as “SusVibes”, found significantly higher functional pass rates than security pass rates in their research:
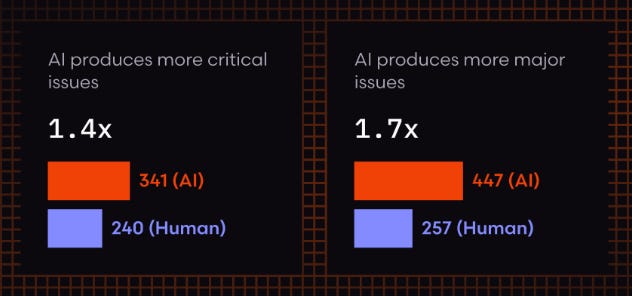
Now for those saying, yes but that research was on earlier models, SonarSource’s analysis of Opus 4.6 itself, published the same day as the Claude Code Security announcement, showed that vulnerability density in code generated by Opus 4.6 has actually increased by 55% compared to its predecessor. Path traversal risks rose 278%. Code smells increased 21%, accompanied by a 50% spike in cognitive complexity. CodeRabbit’s analysis found AI-generated pull requests contained 1.7x more issues and 1.4x more critical security issues than human-written code. AI was 2.74x more likely to introduce XSS and 1.91x more likely to create insecure object reference flaws.
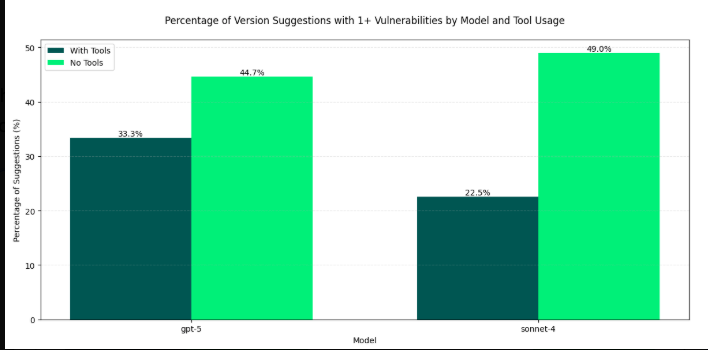
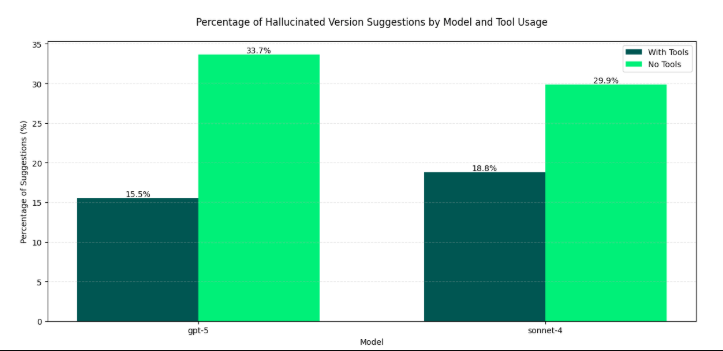
The insecurity of AI-generated code isn’t a fringe finding. As I explored in “Software Dependency Dilemmas in the AI Era,” Endor Labs’ 2025 State of Dependency Management report found AI-generated code is vulnerable 25–75% of the time, with vulnerability rates increasing as task complexity grows. This doesn’t even account for high levels of hallucinated package recommendations too.
The root cause is a garbage-in, garbage-out problem: frontier models are trained on massive public datasets, including open-source software that is itself rife with vulnerabilities. Those flaws get absorbed into training data and passed down through generated code. This is further compounded by hallucinated dependencies, where AI recommends packages that don’t exist or are vulnerable, introducing novel supply chain risks.
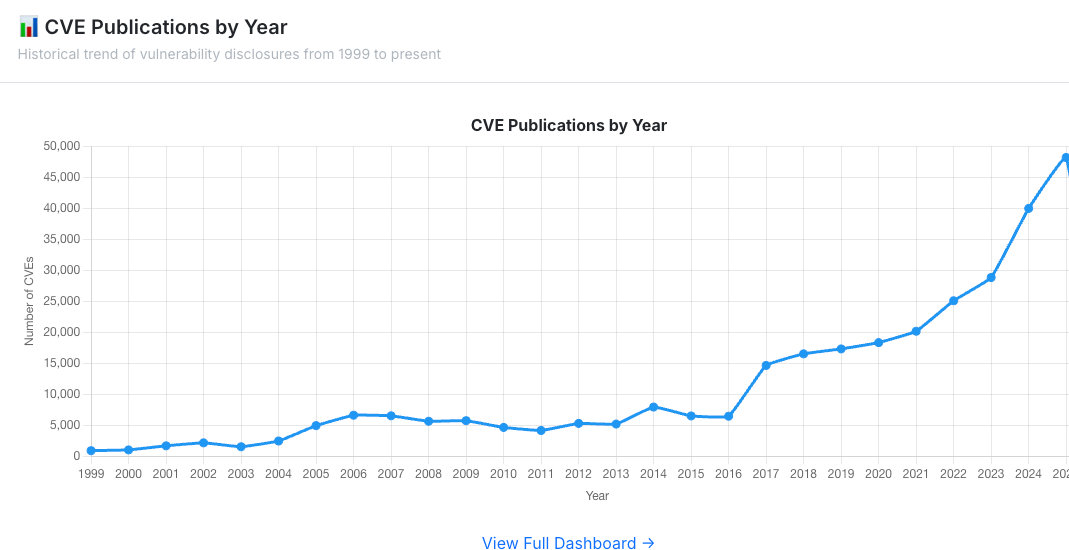
So we have a paradox: the same model that is excellent at finding vulnerabilities in existing code is simultaneously introducing more vulnerabilities when it generates code. As Endor Labs CEO Varun Badhwar pointed out, if AI coding agents could handle security well, the code they generate would already be secure, but it’s not. This underscores a point that Snyk’s Manoj Nair articulated well: AI reasoning is a research assistant, while deterministic validation is the gatekeeper. You can ask an AI to reason about a vulnerability, but you cannot ask a probabilistic model to guarantee compliance, prove data flow, or enforce enterprise policy across thousands of repositories. Discovery Was Never the BottleneckHere’s the uncomfortable truth that gets lost in the excitement over AI-powered vulnerability discovery: finding vulnerabilities has never been the hard part. The hard part is fixing them. The industry doesn’t have a detection deficit, it has a remediation crisis. CVE volume has increased by roughly 490% over the last decade, with over 48,000 CVEs published in 2025 alone. We’re seeing 30% year-over-year CVE growth, and that’s without accounting for the NVD’s historical backlog of nearly 39,000 unenriched vulnerabilities. You can see the exponential growth from CVE.icu, from my friend Jerry Gamblin.
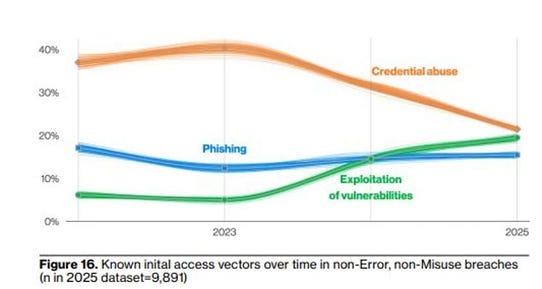
Every organization I talk to is sitting on vulnerability backlogs that are growing faster than they can be triaged, let alone remediated. Adding a more powerful discovery engine to that equation, without fundamentally addressing the remediation bottleneck, risks making the problem worse, not better. I’ve been writing about this for years. When I covered the 2024 Verizon DBIR in “The DBIR is Entering its Vulnerability Era,” vulnerability exploitation had already tripled, growing 180% over the previous year’s report. The DBIR’s own data showed it takes organizations around 55 days to remediate just 50% of vulnerabilities in CISA’s Known Exploited Vulnerability catalog once a patch is available, and by year’s end nearly 10% remain open. As I noted then, simply telling organizations to “patch faster” doesn’t work when the underlying incentive structures are misaligned. By 2025, the picture only got worse. As I laid out in “Vulnerability Velocity & Exploitation Enigmas,” vulnerability exploitation has now overtaken phishing as a primary attack vector according to the DBIR, and Mandiant’s M-Trends report had exploitation as the single most dominant initial infection vector.
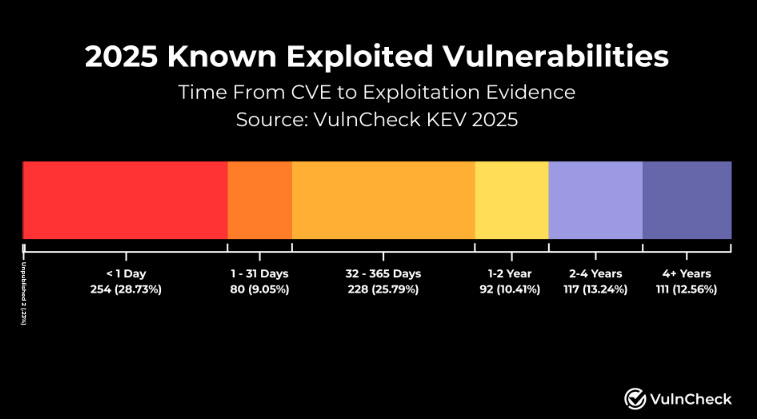
Attackers are having more success with vulnerability exploitation while defenders are struggling more than ever to keep pace. This is supported in the data too, such as VulnCheck’s 2026 State of Exploitation Report, which found that nearly 30% of known exploited vulnerabilities (KEV) are exploited on or before the day their CVE was published, an increase from 23.6% the year prior.
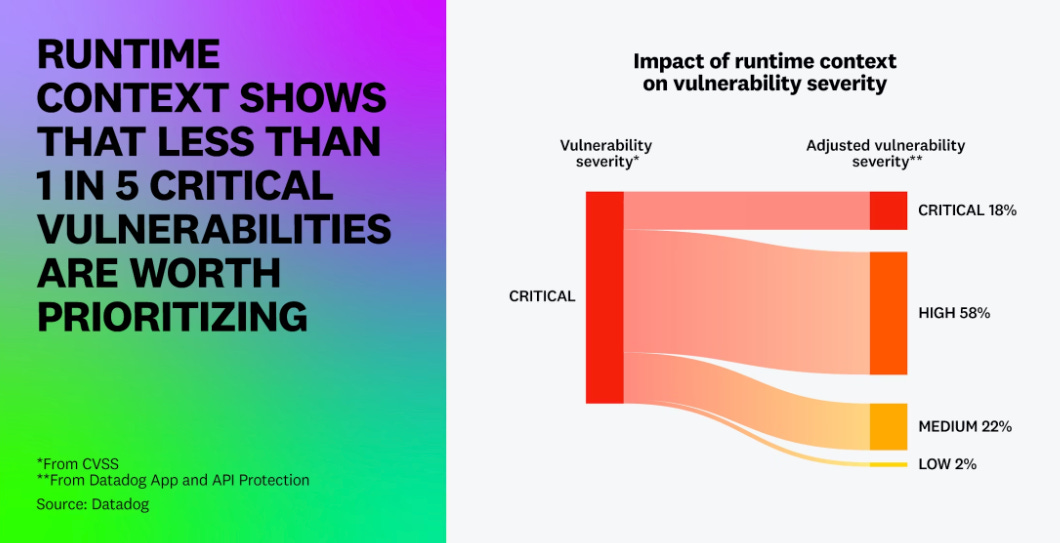
And here’s the critical detail that most of the Claude Code Security commentary overlooks: we know less than 5% of CVEs in a given year are ever actually exploited. Organizations are wasting enormous amounts of time and labor forcing development peers to remediate vulnerabilities that pose little actual risk. This is something the industry has realized, as we’ve seen the rise of efforts around known exploitation, exploitation probability, reachability and other efforts to truly spend finite resources where the real risks reside. This is something I’ve discussed in prior articles, such as “Context is King but Prioritization is Priceless”. The root cause isn’t technical, it’s operational and organizational. Engineering teams are under relentless pressure to ship features, hit revenue targets, and maintain development velocity. Security remediation competes directly with those priorities, and in most organizations, it loses. Product leadership wants releases on schedule. Engineering managers are measured on throughput. Developers are already stretched thin, and asking them to context-switch into fixing vulnerabilities that a scanner flagged, often without sufficient context on exploitability or business impact, is a losing battle. This is why vulnerability backlogs balloon: not because teams can’t find the issues, but because the incentive structures, resource constraints, and competing business interests make sustained remediation operationally brutal. Claude Code Security’s suggestion of targeted patches is a step in the right direction, but even AI-generated patches require validation, regression testing, and deployment through change management processes that move at organizational speed, not model speed. Until the industry confronts the remediation operations problem head-on, including how we prioritize what actually matters, how we integrate fixes into existing workflows without disrupting velocity, and how we align security incentives with business incentives, better discovery will continue to compound backlogs rather than reduce risk. The bottleneck was never “can we find it?” It’s always been “can we fix it, and will the organization let us?” The Structural GapsBeyond the inherent limitations of LLMs and the remediation crisis, there are several structural gaps that the Claude Code Security announcement doesn’t address. Reachability and Runtime Context: Static analysis, whether rule-based or LLM-driven, still operates without runtime context. Knowing that a vulnerability exists in code and knowing that it’s reachable and exploitable in a production deployment are two fundamentally different things. Datadog’s State of DevSecOps report showed that only 20% of “critical” vulnerabilities are actually exploitable at runtime.
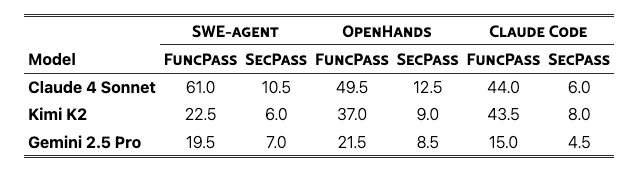
Endor Labs has demonstrated through reachability analysis that 92% of vulnerabilities, without context such as known exploitation, EPSS probability, reachability, existing exploits, and available fixes, are purely noise. As I wrote in “AppSec’s Runtime Revolution,” highlighting Oligo as an example, the industry spent years “shifting left” by jamming low-fidelity, noisy scanners into CI/CD pipelines and dumping massive lists of findings without context onto developers, then wondering why they hated us and dreaded engaging with us. Even Gartner came around to this reality in their research publication “Shift Security Down, Not Left to Scale DevSecOps,” advising the industry to pivot away from shifting-left approaches. Runtime visibility and context matter because at the end of the day, what counts is what is actually running in production, what is reachable and exploitable, and ensuring teams have visibility into application-layer behavior. A frontier model reasoning about source code, however impressive, doesn’t have access to the dependency graph, the deployment topology, or the runtime behavior that determines real-world risk. AppSec teams need reachability analysis, runtime correlation, and exploitability validation to prioritize effectively. Without that context, even the most brilliant AI-driven findings are still just a more sophisticated firehose of alerts. Independent Verification: As Varun Badhwar of Endor noted in a video on his LinkedIn, if your coding agent writes the code and tells you the code is secure, who’s verifying that claim? It’s the same model, the same context window, the same blind spots. This is a structural reality of how security works. You don’t let the developer who wrote the code also sign off on the security review, and the same principle should apply to AI. Enterprise Governance: Security teams need audit trails, compliance reporting, policy-as-code enforcement, role-based access, and the ability to define what “secure” means for their specific organization. James Berthoty of Latio Tech offered a characteristically blunt reality check, noting that the capabilities being announced largely mirror what has already been available in Claude Code’s existing security features, and that the enterprise workflow and governance layer is where the real gap exists. The Competitive Landscape RecalibratesViola Ventures Principal Alon Cinamon offered a compelling framing in Calcalist Tech: Anthropic didn’t kill cybersecurity. They validated that frontier AI is now a real participant in the security market at the exact moment when software velocity, data-source sprawl, and attacker automation are all accelerating. This acceleration is collaborated in recent reports too, such as Crowdstrike’s 2026 Global Threat Report, see below:
The market reaction, while dramatic, is pricing in a category-level shift rather than a product-level displacement. When reasoning becomes cheaper, value shifts away from products that mainly generate alerts and toward systems that can ingest multiple data sources, correlate reliably, prioritize with evidence, and execute remediation with guardrails and auditability. Cinamon correctly identified that this isn’t just about AppSec: any category selling “rules plus dashboards plus triage” is exposed. But he also emphasized that this makes the challenge more complex, not less. CISOs aren’t being replaced; they’re being handed a new mandate to “run security at machine speed across more systems with less tolerance for noise”. We’ve seen this movie before with cloud security, where every major CSP built native monitoring and posture management capabilities that were supposed to eliminate standalone vendors. And yet Datadog built a $40B+ business and Wiz was acquired by Google for $32B. The platform providers validated the problem; the focused companies built the products that actually solved it. Where This All Lands
I’ve been arguing for a while that cybersecurity needs to pivot from being a typical late adopter and laggard to being an early adopter and innovator with AI. Claude Code Security reinforces that urgency. The capabilities are improving at the pace of model releases, not product roadmaps, and that’s a competitive reality that every AppSec vendor and practitioner needs to internalize. But the path forward isn’t LLMs replacing AppSec, it’s LLMs becoming a powerful layer within AppSec, coupled with deterministic analysis for trust, reachability analysis for prioritization, runtime context for real-world risk assessment, and enterprise governance for operational readiness. The idea that we will continue to apply the methods of the past, even approaches from the “shift left” and DevSecOps era where we threw a bunch of noisy, low-fidelity tooling into CI/CD pipelines and then dumped massive lists of findings without context onto developers, is outright foolish. What got us “here,” which isn’t a good place, certainly won’t get us “there.”, and Claude Code Security, for all its genuine capability, is still fundamentally a discovery and patching tool operating in the static analysis paradigm. It doesn’t solve for the organizational dynamics, the remediation operations challenge, or the runtime context gap that define the actual hard problems in AppSec. The organizations and vendors that will thrive are those building the full stack of modern AppSec: frontier AI reasoning for discovery and contextual analysis, deterministic validation for the trust baseline, runtime and reachability correlation for exploitability, automated remediation loops that close findings at scale, and governance and policy enforcement that meets enterprise requirements. That’s the architecture that wins, not a single model or a single tool, no matter how capable. The frontier labs aren’t just adjacent to cybersecurity anymore. They’re in it. And the vendors, practitioners, and organizations that adapt fastest to this new reality, leveraging these capabilities rather than competing against them, will define what AppSec looks like in the agentic era.
(Shout out to others such as James Berthoty, Ross Haleliuk, Varun Badhwar, Ken Johnson and others who have also written on this topic and who’s perspectives I’ve enjoyed). Invite your friends and earn rewardsIf you enjoy Resilient Cyber, share it with your friends and earn rewards when they subscribe.
|




Similar newsletters
There are other similar shared emails that you might be interested in: