Critical AI Security Guidelines
- Chris Hughes from Resilient Cyber <resilientcyber@substack.com>
- Hidden Recipient <hidden@emailshot.io>
Suppose you’ve been in cybersecurity for some time. In that case, you’ve inevitably heard of resources such as the “Critical Security Controls”, or now, as they’re called, the CIS Controls, run by the Center for Internet Security. These are controls many consider fundamental to conducting effective cybersecurity for organizations. You’ve also likely heard of similar leading cybersecurity organizations, such as SANS, which provides cybersecurity training, education, and resources. I have taken multiple SANS courses in my cyber career, and their training is among the best. It is incredibly in-depth, and you always learn a ton. Not to mention, it is taught by some of our industry’s brightest. With the rise of AI, many may argue that we need “AI Security Critical Controls” or at least some guidelines. Luckily, SANS has provided just that in its “Draft: Critical AI Security Guidelines, v1.2.” I wanted to unpack these guidelines for the community, so I’ll dive into their publication and how it ties to broader industry AI security initiatives, news, incidents, and more through this post. So, here we go!
First, it’s worth noting that the contributors to the AI Security Guidelines read like a who’s who in cybersecurity: folk such as Rob Lee, Chris Cochran, Ron Del Rosario, Ken Huang, Sounil Yu, and many others who are industry leaders and many of whom I’ve had the chance to collaborate with to some extent.
Interested in sponsoring an issue of Resilient Cyber? This includes reaching over 45,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives Reach out below! Critical CategoriesSANS starts off the guide by defining what they dub “critical categories” for GenAI security, seen below:
Now with the categories defined, we can step through those control categories from the guidelines to see how SANS recommends approaching each category. Access ControlSANS approaches AI security access control by restricting access to models, databases, and inference processes to limit unintended outcomes or risks. This includes key security principles such as the least privilege and least permissive access control. With unauthorized access, malicious actors could impact the deployed model, the integrity of the code involved, or even how the models make decisions (e.g., weights, training data, etc.). Another key risk is preventing runtime model theft, something another great resource, the OWASP AI Exchange discussions and lists, mitigating controls such as model access control or model obfuscation:
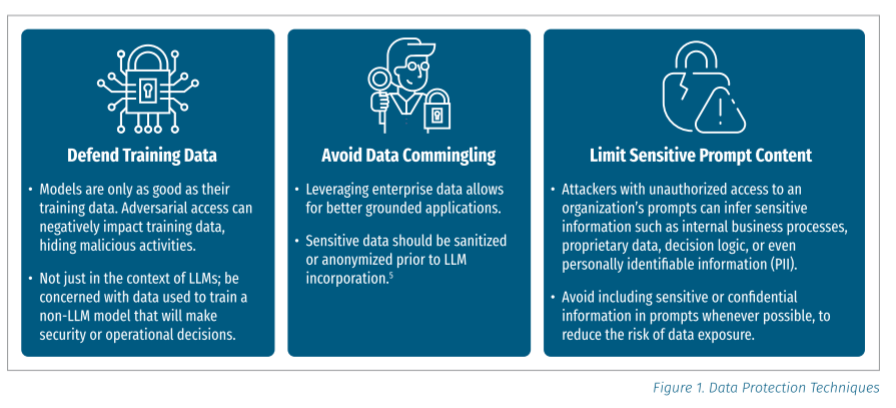
SANS additionally recommends key controls, such as encrypting data at rest and protecting databases involved in use cases such as Retrieval-Augmented Generation (RAG). While not specifically mentioned in the SANS guide, I also wanted to emphasize the importance of securing credentials. Implementing least permissive access control and other fundamental techniques is one thing, but unsecured credentials, as described by MITRE’s ATLAS, for example, occur when adversaries find and obtain insecurely stored credentials and look to exploit them. This problem is poised to grow exponentially, with the explosive growth of non-human identities, as agentic AI, where Agents will have identities and credentials associated with them, which can be abused to compromise access control. Data ProtectionMoving on from Access Control, the next control category they cite is Data Protection. SANS discusses the need to protect AI model training data and data based on AI deployment models (e.g., local vs. SaaS, for example). Some of the data protection techniques they cite include defending training data, avoiding data commingling, and limiting sensitive prompt content:
We’ve already seen several notable examples of organizations failing to implement these techniques, especially when including sensitive data in prompts, such as when Samsung employees put sensitive corporate data into ChatGPT. Of course, the fear around this is that the data can be subsequently used in model training and/or inadvertently exposed to other users without a need to know. This can also be used as part of exfiltration techniques, such as LLM Data Leakage, where adversaries craft prompts to induce LLMs to leak sensitive data such as user data, IP, or other sensitive information. As organizations consider deployment strategies, SANS AI Security Guidelines discuss different hosting options, such as Local vs. SaaS models. In my opinion, we will inevitably see hybrid models, where large enterprises may self-host some models locally (typically in their cloud IaaS environments, such as AWS, GCP, or Azure, including using native services such as an AWS Bedrock) and consume models as-a-service (e.g., ChatGPT, Gemini, etc.). al) This makes it much more of a situation where organizations need to consider security in both scenarios rather than one or the other. Self-hosted options require sufficient infrastructure security and considerations around the open source models being used for building upon. In contrast, SaaS comes with typical third-party risk management considerations and novel aspects of AI risks and security, such as how the model providers may use your data. SANS also discusses the use of AI IDEs, such as VSCode, Windsurf, and Cursor, which are integrated with models and LLMs to improve developers' productivity. These IDEs present a potential pathway where developers may inadvertently expose sensitive data and, in some cases, even serve as tools of the attacker. We’ve seen several examples of this recently, when Anthropic announced that a hacker used Claude to extort 17 companies, or the Nx supply chain attack, where AI coding assistants were used to search for sensitive data on developer systems. Public Model RisksOne thing I was glad to see explicitly mentioned in the guide is the risks of public models. While, as I mentioned above, there are SaaS and third-party risks associated with as-a-service models delivered by frontier model providers, there are also risks associated with platforms such as HuggingFace and the massive volumes of datasets and models on their platforms.
Much like broader Open Source Software (OSS), these models come with challenges such as the potential for malicious code, tampering, and unknown pedigree/provenance. On one hand, the benefit is the transparency that comes with the models being open source or public, but this comes along with the constraints of not enough eyeballs in some cases, as models or projects are often maintained by individuals or a small group of individuals. There is also the potential for software supply chain attacks, as attackers look to distribute compromised models and datasets to users in the community. These risks aren’t just hypothetical either. We’ve seen examples such as hundreds of malicious models using Pickle files, model and dataset poisoning, attempted backdoors, and more. These attempted attacks are not necessarily the fault of HuggingFace and are tied to the open and distributed nature of platforms such as HuggingFace, GitHub, and others in the open source community. SANS rightly calls out key security measures, such as securely hosting internal models for developers' use, red teaming imported models, and leveraging resources such as the OWASP AI Supply Chain Guidance.
This guidance addresses risks such as third-party package vulnerabilities, outdated models, and vulnerable pre-trained models. Inference SecurityFollowing up on the data focus, the next key security category is Inference Security. Think of Inference as the “action phase” where models function in production, performing tasks and ingesting data to provide outputs. Data is input, the model processes it, and outputs are generated. SANS cites guardrails and methods such as input/output validation to keep models behaving properly and avoiding undesired outputs. Some of the key activities they cite for this category of control include:
They discuss the necessity of guardrails and even using cloud-native guardrails such as AWS’ Bedrock, among others—this attempts to avoid unintended outputs or behavior by models. We discussed earlier how prompt injection is one of the most nefarious attack vectors against LLMs. Therefore, SANS cites the need to preprocess both prompt inputs and model outputs to avoid potential impacts. Making prompt injection even more nefarious, LLM prompt injection can be done both directly and indirectly, with malicious actors embedding prompts into benign resources that models process, including everything from emails, web pages, Jira tickets, and more, and countless examples of this have been demonstrated already. Researchers have already demonstrated how the leading enterprise AI platforms, such as ChatGPT, Microsoft Copilot, Google’s Gemini, and Cursor/Jira, are all vulnerable to these attacks. These attacks can even be done with zero clicks while still leading to unauthorized access, data exfiltration, and more—for a great example, see “AgentFlayer.” With the rise of Agentic AI and protocols such as MCP, some of these risks will become even more pertinent, such as excessive agency, also cited in the LLM Top 10, as LLM08.
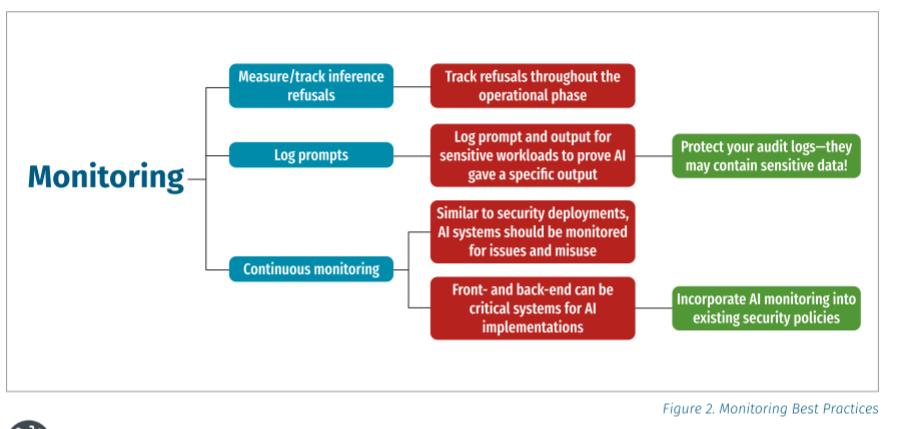
LLMs, specifically agents, can have excessive autonomy, functionality, and permissions, leading to damaging actions and cascading impacts. What’s scary about this particular risk, in my opinion, is that historically, we have struggled terribly with basic controls such as least-permissive access control for human users. Some estimates suggest that non-human identities and agents are poised to outnumber human users by as much as 50-1. Given our abysmal track record, how do well do you think we will manage that identity and permission sprawl? Yeah, me too. Rounding out the Inference Security section, SANS makes other recommendations, such as monitoring and controlling API usage, which makes sense as observing APIs can help identify anomalous and potentially malicious activities. MonitoringLogging and monitoring have long been security best practices, and nothing changes here regarding AI applications, LLMs, and agents.
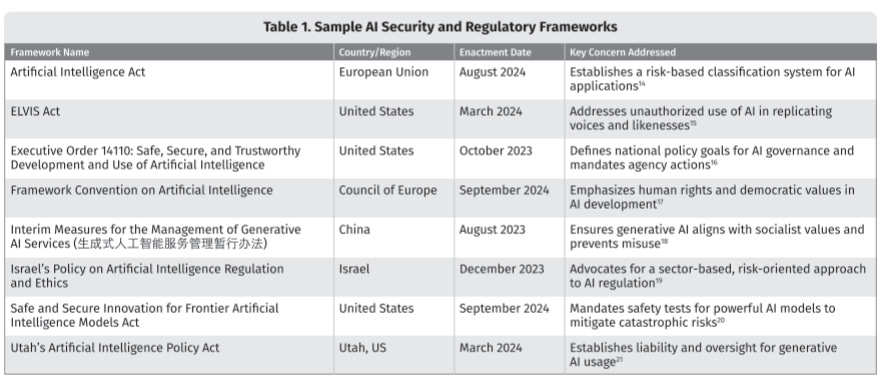
That said, there are challenges with monitoring in various scenarios, such as when you’re consuming models as-a-service and don’t have visibility into the underlying infrastructure or hosting environment (similar to SaaS, for example), and scale, as I mentioned earlier, with agents poised to outnumber human users exponentially. We’re seeing innovative solutions come to market to try and address the latter challenge, for example, focused on agent visibility and governance. Governance, Risk, and ComplianceAh, everyone’s favorite punching bag in cybersecurity, GRC. Now, I know many will bemoan compliance with the usual trope of “compliance doesn’t equal security”, and I would shoot back that I once held that naive view, but I’ve now come around to accept that in the absence of compliance, the state of security would be far worse than it is now, as compliance is the primary driver of getting the business to even care about security to begin with. This is a point I laid out in painstaking detail in a post titled: “Compliance Does Equal Security - Just Not the Elimination of Risk”. SANS makes the point that organizations must ensure their AI initiatives are aligned with applicable industry regulations to ensure compliance. They provide an example of AI security and regulatory frameworks:
It’s worth noting that some of these are not entirely relevant anymore, especially the U.S. 14110, which the current presidential administration has rescinded. That said, there are still several relevant state-level AI regulations that U.S. organizations should be familiar with, such as: And of course, we will eventually see Federal U.S. AI regulations, either upon a presidential administration change. One that is more focused on regulation, or as businesses grow weary of navigating the patchwork quilt of state-level regulations and lobby for an overarching Federal AI regulation. Internationally, the EU AI Act is the elephant in the room, and most organizations doing business globally will need to navigate it to some extent. SANS calls for organizations to implement GRC practices such as:
If you want a deep dive on AIBOMs in particular, you can see my conversation with Helen Oakley, “Exploring the AI Supply Chain”  GRC and regulations aside, one of my favorite aspects of the entire AI Security Guideline from SANS was this line:
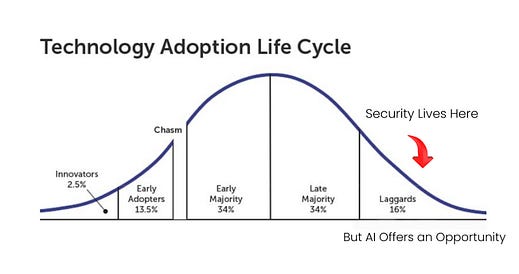
This is something in my opinion that all cybersecurity practitioners need to sit and soak in. Not only do attempts to block or disallow AI lead to shadow usage, which SANS points out, but it also perpetuates age of problems in cybersecurity with us being a late adopter and laggard of technological waves, while both our business peers and adversaries alike lean into the emerging technology innovate, and become more effective.
This is a point I have tried to make myself, in articles prior:
Suppose we want to break the cycle of security being bolted on. In that case, we need to shift from being laggards in cybersecurity to innovators and early adopters of the technology adoption lifecycle. Incident Response and Forensics for AI SystemsStepping down off my little rant about cybersecurity being a laggard, the final control category in the SANS AI Guideline is Incident Response and Forensics. SANS highlights how this control will be specifically critical as we see the rise of agents and agentic AI workflows, with external tool usage, the potential for cascading failures and the need to govern agents that exponentially outnumber human users in enterprise environments. AI does indeed present new and novel attack vectors and types, such as model poisoning, prompt injection, data leakage through outputs being generated and model extraction to name a few. SANS recommend organizations conduct key activities, such as:
I wanted to point folks to a couple of additional resources I know would be helpful as well, such as: As organizations continue to lean into AI adoption, utilizing GenAI, implementing Agentic AI architectures and more, it is critical that they revisit their Incident Response Plans (IRP)’s to account for the novel aspects and considerations of AI, whether for self-hosted models and implementations, or consuming AI via as-a-Service models. Closing ThoughtsThe SANS Critical AI Security Guidelines represents a great resource for the community, covering critical control areas and helping position CISO’s and security teams to tackle them. As organizations continue to rapidly adopt GenAI and soon Agentic AI, resources such as this will be key to facilitate secure AI adoption. Resilient Cyber is free today. But if you enjoyed this post, you can tell Resilient Cyber that their writing is valuable by pledging a future subscription. You won't be charged unless they enable payments.
|





Similar newsletters
There are other similar shared emails that you might be interested in: