The Sequence Radar #824: Last Week in AI: Sovereign Lobsters, Self-Coding Agents, and Gigawatt Factories
Was this email forwarded to you? Sign up here The Sequence Radar #824: Last Week in AI: Sovereign Lobsters, Self-Coding Agents, and Gigawatt FactoriesMajor releases from Google and Anthropic, a fun project from Karpathy and massive compute deals.
Next Week in The Sequence:
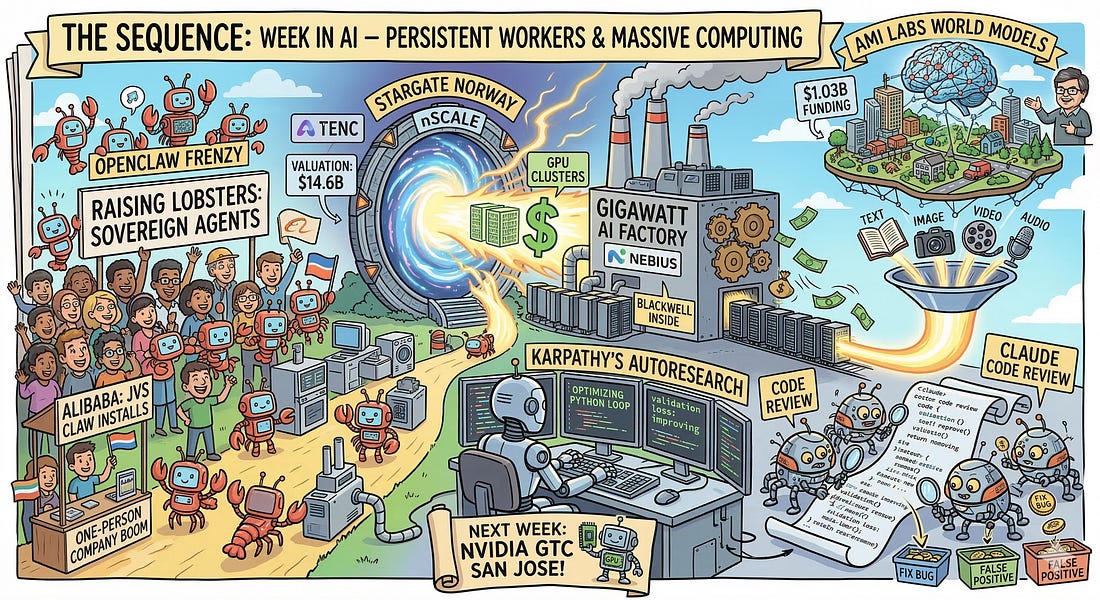
Subscribe and don’t miss out:📝 Editorial: Last Week in AI: Sovereign Lobsters, Self-Coding Agents, and Gigawatt FactoriesWelcome to The Sequence. If this week proved anything, it is that we have decisively crossed the threshold from AI as a conversational assistant to AI as an autonomous, persistent worker. From self-improving research loops to massive sovereign agent deployments in Asia, the infrastructure and application layers of AI are evolving at a breakneck pace. Let’s start with the most fascinating glimpse into our automated future: Andrej Karpathy’s Autoresearch. Karpathy has open-sourced an autonomous optimization loop where an AI agent iteratively modifies its own PyTorch training scripts. Operating with a strict five-minute compute budget per experiment, the agent generates hypotheses, edits code, runs the training, and evaluates validation loss. If the change improves performance, the agent commits the code. It is the scientific method running at machine speed—a profound paradigm shift where AI models actively improve themselves while researchers sleep. Anthropic is applying a similar multi-agent philosophy to software engineering with the launch of Claude Code Review. Moving far beyond traditional syntax linters, this system deploys multiple specialized Claude agents in parallel to analyze GitHub pull requests. They cross-check codebase logic, filter out false positives, and rank deep contextual bugs that rushed human reviewers routinely miss. With an astonishingly low false-positive rate and high internal adoption, Anthropic is proving that multi-agent collaboration is the new standard for enterprise code verification. Meanwhile, a massive consumer and enterprise agent wave is sweeping China, driven by the open-source OpenClaw phenomenon. Dubbed “raising lobsters” by locals (a nod to the project’s crustacean mascot), OpenClaw allows users to run persistent, locally-hosted AI agents capable of controlling operating systems and executing complex workflows. The frenzy is so intense that Alibaba just debuted “JVS Claw,” a mobile app designed to help non-coders install and deploy OpenClaw agents in minutes. Tech giants like Baidu and Tencent are also racing to provide OpenClaw cloud infrastructure, fueling a “one-person company” boom even as Beijing authorities scramble to address the inherent security risks of sovereign agents with deep system access. But perhaps the clearest signal that the industry is looking beyond traditional LLMs to power these autonomous systems comes from AI pioneer Yann LeCun. The former Meta AI chief just secured a staggering $1.03 billion seed round—Europe’s largest ever—valuing his new Paris-based startup, AMI Labs, at $3.5 billion. Instead of chasing the next generative text model, AMI is doubling down on “world models.” Designed to learn abstract representations of physical reality, these systems aim to reason, plan, and understand cause and effect without the hallucinations that plague autoregressive models. Backed by heavyweights like Nvidia, Bezos Expeditions, and Temasek, LeCun’s massive bet highlights a fundamental shift from language prediction to true, grounded machine intelligence. Of course, this explosion in autonomous agents and world models requires staggering amounts of compute. This week saw historic capital events in the AI infrastructure layer. London-based nScale secured a massive $2 billion Series C, catapulting its valuation to $14.6 billion as it scales its “Stargate Norway” GPU clusters. Simultaneously, Amsterdam’s Nebius is riding an incredible 700% ARR growth wave, aggressively raising capital and deploying gigawatt-scale AI factories equipped with next-generation NVIDIA Blackwell chips. The physical backbone of the AI revolution is attracting unprecedented capital. Finally, on the model front, Google released Gemini Embedding 2. This is a massive leap forward for Retrieval-Augmented Generation (RAG). As Google’s first natively multimodal embedding model, it projects text, images, video, audio, and documents into a single, unified vector space. Developers can now process interleaved modalities in a single API call, fundamentally transforming how enterprise data is indexed and retrieved. From autonomous coding loops to sovereign lobsters and gigawatt GPU factories, the AI stack is maturing across every layer. 🔎 AI ResearchExamining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-TrainingAI Lab: Meta Superintelligence Labs and Yale University Summary: This paper investigates the effectiveness of using reasoning large language models as judges for reinforcement learning-based alignment in domains where output correctness cannot be directly verified. The authors discover that while reasoning judges outperform non-reasoning ones in preventing standard reward hacking, they inadvertently train policies to achieve high scores by generating sophisticated adversarial outputs that deceive evaluators. AI Must Embrace Specialization via Superhuman Adaptable IntelligenceAI Lab: Columbia University, Distyl, and New York University Summary: This paper argues that the pursuit of Artificial General Intelligence (AGI) is conceptually flawed because human intelligence is fundamentally specialized rather than universally general. Instead, the authors propose shifting the field’s focus toward Superhuman Adaptable Intelligence (SAI), which emphasizes an AI’s ability to rapidly learn and achieve superhuman performance on specific, high-utility tasks using self-supervised learning and world models. RbtAct: Rebuttal as Supervision for Actionable Review Feedback GenerationAI Lab: Collaborative Research Summary: The authors propose RbtAct, a method that leverages existing peer review rebuttals as implicit supervision to train large language models to generate more actionable, specific, and implementable review feedback. By fine-tuning and applying preference optimization on a newly curated dataset (RMR-75K) that maps reviews to author rebuttals, the resulting model significantly improves the practical usefulness of AI-generated peer reviews. Code-Space Response Oracles: Generating Interpretable Multi-Agent Policies with Large Language ModelsAI Lab: Google DeepMind Summary: This paper introduces Code-Space Response Oracles (CSRO), a framework that replaces opaque deep reinforcement learning oracles in multi-agent systems with Large Language Models (LLMs) to generate human-readable policy code. By reframing best-response computation as a code generation task and utilizing techniques like zero-shot prompting and distributed evolution, CSRO achieves competitive game-theoretic equilibria while producing highly interpretable and explainable strategies. AgentRx: Diagnosing AI Agent Failures from Execution TrajectoriesAI Lab: Microsoft 🤖 AI Tech ReleasesClaude Code ReviewAnthropic released Claude Code Review, an agentic system for code reviews. Gemini Embedding 2Google released Gemini Embedding 2, its first multimodal embedding model across 6-7 modalities. Nemotron 3 SuperNVIDIA released Nemotron 3 Super, a 120 billion parameter model optimized for agentic tasks. AutoresearchAndrej Karpathy open sourced autoresearch, self-contained agents for fast research. 📡AI News You Need to Know About
You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|


Similar newsletters
There are other similar shared emails that you might be interested in: