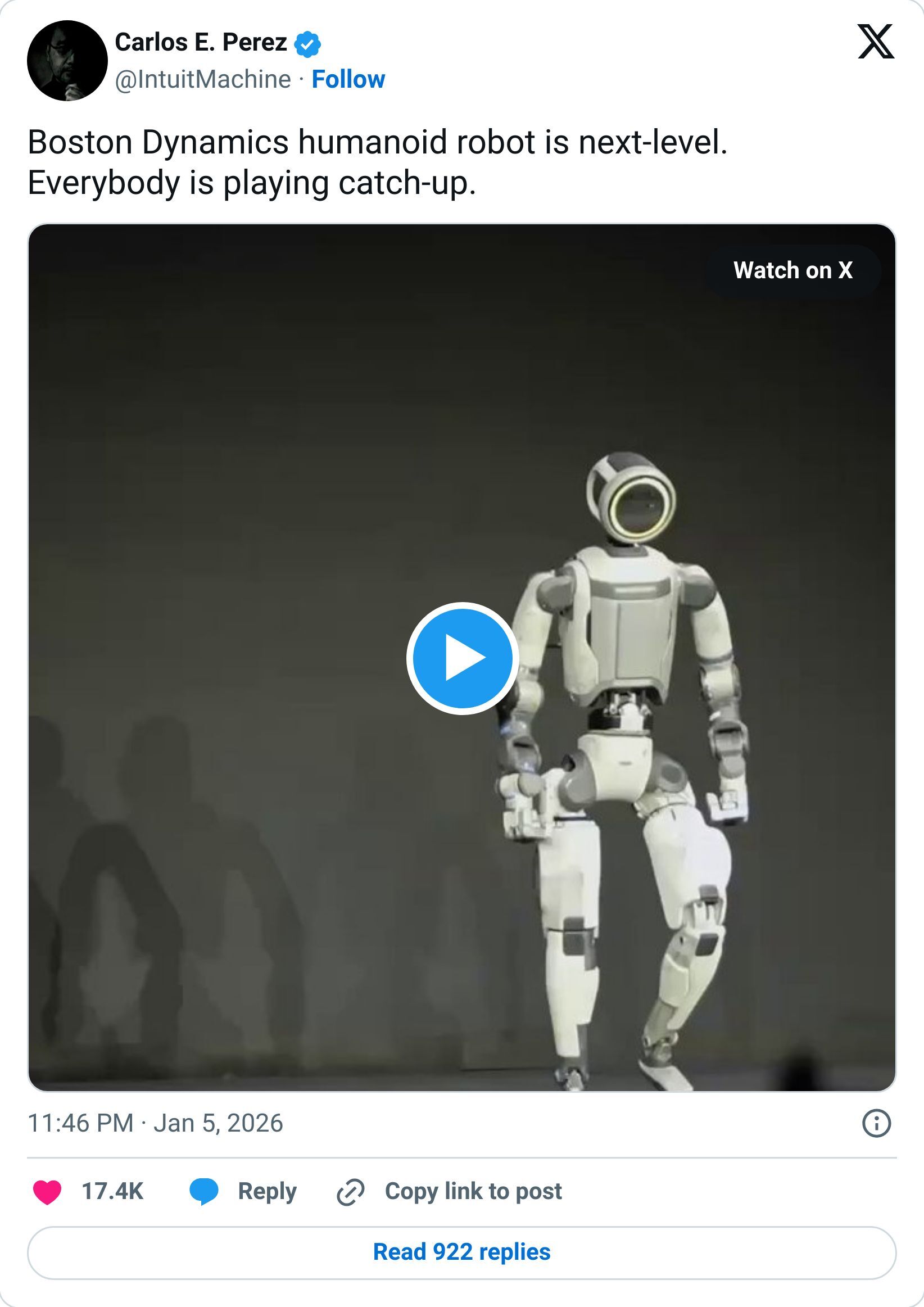
This Week in Turing Post: |
|
If you like Turing Post, consider becoming a paid subscriber or sharing this digest with a friend. It helps us keep Monday digests free → | |
|
|
Hello from CES 2026, the world’s largest consumer electronics gathering, where the pace of change has reached a point where predicting what comes next feels more like staring at an event horizon than drawing a roadmap. It’s striking how much strategic scheduling can shape perception. Judging by media coverage alone, you might conclude that CES 2026 revolved around Jensen Huang again. In practice, NVIDIA placed Jensen Huang’s “special presentation” at 1:00 p.m. PT, a high-attention slot. CES’s official opening keynote, delivered by Lisa Su, AMD’s CEO, ran in the evening, when many attendees were already running low on attention. |
I attended three chip-focused presentations at CES on Monday – Qualcomm, NVIDIA, and AMD — to see the whole picture. And this editorial reflects that. First, I’ll cover what announcement excited me the most and what it matters for our future. Second, I’ll draw you the picture of the real competition between infrastructure giants and the futures they are optimizing for. |
Part 1, what excited me most: Alpamayo, and what it means for Tesla and self-driving cars in general |
During his keynote, Jensen Huang presented Alpamayo 1 – a reasoning-based vision–language–action (VLA) model for autonomous driving, developed alongside large-scale simulation and synthetic data pipelines. “Simulation is where we are the most comfortable,” he said. And I wasn’t sure if it’s purely technical or metaphorical as well. Alpamayo 1 is roughly a 10-billion-parameter model, designed to take multimodal inputs such as surround camera feeds, vehicle history, and navigation context, and produce driving trajectories together with explicit reasoning traces. Those traces make decisions inspectable, which is critical for validation, debugging, and safety review. It took them 8 years to develop this model and NVIDIA Drive AV system based on that. |
This reasoning VLA treats driving as a continuous decision-making process rather than a collection of scripted responses. This matters for a long-running debate in autonomous driving: sensors versus intelligence. Alpamayo strengthens the case that LiDAR-heavy architectures were, at the very least, overemphasized. If a system can reason about scenes, infer intent, and generalize from prior experience, it does not need a sensor suite that reshapes the vehicle into a rolling research prototype. That opens the door to cars that are not only safer, but also lighter, more energy-efficient, and visually closer to what consumers actually want to drive. |
Tesla demonstrated this path first. And they’ve been successful with their full self-driving (FSD) system. But they haven’t yet fully solved the autonomy. |
|
What Elon Musk means is that getting to 99% is achievable – solving the last one percent is brutally hard. The long tail is made of rare, ambiguous, poorly labeled scenarios that defeat pattern recall. That is where open-sourced Alpamayo family (that includes Alpamayo 1, AlpaSim, and datasets) becomes structurally important. By pairing reasoning models with simulation and by open-sourcing key components, NVIDIA is proposing a shared foundation for autonomy, one that allows multiple carmakers to build compatible, safety-validated systems without copying Tesla’s exact approach. |
Does Alpamayo solve the autonomy problem? It doesn’t. But it changes how the industry works on it. That is why I’m excited. By open-sourcing models, data, and simulation tools, NVIDIA is proposing a shared foundation for autonomy. I keep returning to this point because it matters. The signal here is a transition to a new chapter, one with more participants, shared assumptions, and more ways to make progress on the hardest parts of the problem. (btw NVIDIA's autonomous vehicle team is 7,000 people, means ~20% of NVIDIA employees work on autonomous cars, according to Ben Bajarin. Pretty serious commitment). |
Part 2: It Matters Where AI Runs |
The central insight across Qualcomm, NVIDIA, and AMD is that AI is reorganizing computing around where it runs, not around a single “best” chip. |
Qualcomm’s Snapdragon X2 narrative is the clearest window into the client-side surface. The presentation kept returning to always-on experiences and the practical problem of running them without draining the battery or spiking fan noise. Snapdragon X2 Plus and X2 Elite are pitched around an ~80 TOPS NPU baseline, paired with an ecosystem story: Windows features and third-party applications shifting specific workloads onto the NPU. |
This is not a subtle change. If a PC is expected to summarize threads, caption audio, enhance video, and power “settings agents” continuously, then the NPU stops being a checkbox and becomes the always-on subsystem that keeps the rest of the machine stable. Microsoft’s presence onstage reinforces the architectural premise: hybrid AI is the long-term design (we will be talking about Hybrid AI more in the upcoming articles), with cloud models reserved for heavy reasoning and local compute handling latency-sensitive background tasks. |
 | James Howell from Microsoft at Qualcomm presentation |
|
NVIDIA is working on the opposite end of the spectrum: centralized compute and physical deployment loops. Vera Rubin is the flagship proof. NVIDIA describes it as a rack-scale platform composed of multiple tightly integrated components including the Vera CPU, Rubin GPU, NVLink switch generation, ConnectX networking, BlueField DPU, and Spectrum-X networking, with strong emphasis on throughput, cost per token, and trusted computing features. |
|
Vera Rubin is the “AI factory” surface, aimed at training and large-scale inference where the limiting factors are memory bandwidth, interconnect, power delivery, and utilization. |
Alongside that, NVIDIA is extending the stack outward into the physical world via its “physical AI” package: world and robotics models, simulation tooling, and edge modules. The pre press-brief was explicit about a closed loop that spans training, simulation and validation, and deployment on robot and vehicle-class hardware. Alpamayo is positioned as an open reasoning VLA model for autonomous driving. Jetson T4000 anchors the deploy surface as a Blackwell-based module, described as a production-friendly upgrade path for robotics developers. As always, NVIDIA also provided the best show. |
|
AMD’s keynote stitches the two worlds together. Lisa Su’s framing is an explicit bet on heterogeneity: cloud racks, PCs, edge, and scientific systems all sit on the same demand curve. “AI Everywhere, for Everyone,” was repeated a few times. AMD’s Helios rack-scale platform and MI455 accelerators represent its data center surface, built to scale training and inference with tightly integrated CPU, GPU, and networking. On the client side, AMD emphasizes Ryzen AI systems and OEM breadth, which is a parallel attempt to make local AI compute a default property of mainstream PCs, even if the NPU numbers differ from Qualcomm’s messaging. |
Lisa Su also pulled up a heavyweight lineup with Fei-Fei Li (World Labs), Greg Brockman (OpenAI), Ramin Hasani (Liquid AI), Michael Kratsios (U.S. Office of Science and Technology Policy), John Couluris (Blue Origin) and others. |
 | Lisa Su and AMD is doubling down on AI education (in partnership with the government) |
|
When you look at all of this together, the competitive picture becomes clearer. Qualcomm is making continuous local inference feasible at consumer price points. The ambition is focused and pragmatic: ensure that always-on AI can run locally, efficiently, and predictably, without relying on constant cloud access. |
AMD is building continuity across cloud and device while offering full portfolios. The ambition is infrastructural. AMD is positioning itself as the connective layer across racks, PCs, and edge systems, assuming that heterogeneity is not a temporary phase but a permanent condition of AI computing. |
NVIDIA is turning AI into an industrial system that spans centralized compute, simulation pipelines, and edge deployment. The ambition is systemic. By coupling large-scale platforms with simulation-first development and physical AI tooling, NVIDIA is aiming to control the loop by which intelligent systems are built, validated, and deployed in the real world. |
Overall, extremely exciting times. Do you think, it is the moment when singularity begins? |
We are reading |
|
|
|
12 New Advanced Types of RAG | RAG is one of the hottest topics. And this week, we’re lucky to see some truly exciting new research on RAG | www.turingpost.com/p/12ragtypes |
| |  |
|
|
|
|
News from the usual suspects |
Meta Buys Time
Meta’s $2B acquisition of Manus looks less like a roadmap and more like a reaction. The company is absorbing an orchestration-first agent built to complete complex tasks autonomously – but the timing suggests urgency, not clarity. Especially considering that Chief AI Scientist Yann LeCun announced his departure to launch AMI, a new research-focused AI lab. For all of Meta’s AI posturing, coherence may be slipping. It feels like Mark Zuckerberg doesn’t know what he is doing exactly. And Yann LeCun, on his way out of Meta, was very precise in his latest, very honest interview to FT, saying: “We suffer from stupidity.” Boston Dynamics + DeepMind [Brains Meet Brawn]
Boston Dynamics and Google DeepMind are teaming up to put real brains behind those robotic biceps. Their new partnership, unveiled at CES 2026, fuses DeepMind’s Gemini Robotics AI with the next-gen Atlas humanoid. From robotic athletes to robots that think like engineers – this alliance gears up to reshape industrial automation.
|
|
Amazon [Alexa Ascends]
At CES 2026, Amazon rolled out a unified AI vision, with Alexa+ taking center stage across web, mobile, and now third-party devices – from BMW dashboards to Bosch coffee makers. Meanwhile, Ring gets smarter with fire detection and its own app store, and Fire TV turns art curator. All roads now lead to Alexa.com, Amazon’s bid to become your all-knowing, ever-present digital concierge.
|
Models |
|
|
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Train a small model from scratch with long-context support and an agent-centric curriculum to internalize planning, reflection, and tool use without relying on distillation →read the paper Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Shift computation from uniform token processing to dynamically learned semantic concepts to allocate more capacity to reasoning-critical transitions under fixed compute budgets →read the paper
|
|
Research this week |
(🌟 indicates papers that we recommend to pay attention to) |
Make model architectures scale stably |
🌟🌟 mHC: Manifold-Constrained Hyper-Connections (by DeepSeek – we will be covering this concept and this paper on Wednesday in more detail)
Restore identity-like behavior in widened residual streams by projecting hyper-connections onto a constrained manifold to reduce training instability and improve scalability while keeping efficiency in check →read the paper Deep Delta Learning
Generalize residual updates by learning a data-dependent rank-1 “delta” transform that can interpolate between identity, projection, and reflection to model richer state transitions without blowing up optimization →read the paper
|
Make learning itself more expressive and continual |
🌟🌟 Nested Learning: The Illusion of Deep Learning Architectures (by Google Research)
Reframe learning as nested optimization with context flow to interpret optimizers as memory, motivate self-modifying update rules, and build continuum memory for continual learning behavior →read the paper
|
Make reasoning observable, steerable, and trainable |
🌟 Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process (by Google DeepMind)
Discover disentangled “reasoning vectors” with sparse autoencoders on step-level activations to identify behaviors like reflection and backtracking and then modulate them without retraining →read the paper 🌟 Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Improve reasoning by training on synthetic chain-of-thought distributions that better match the learner model, even when final answers are wrong, to harvest partially correct structure and better learning signals →read the paper Scaling Open-Ended Reasoning to Predict the Future
Train forecasting-focused reasoning with synthesized questions and retrieval plus reward shaping to improve accuracy and calibration on open-ended prediction tasks →read the paper
|
Make modular models route and specialize better |
|
Make long-context reasoning and memory work |
🌟 Fast-weight Product Key Memory (be Sakana AI)
Turn product-key memory into an episodic fast-weight store by updating it through local gradient steps during training and inference to memorize fresh key-value pairs and improve long-context recall →read the paper 🌟 Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling (by WeChat)
Evolve retrieved facts into a hypergraph memory that explicitly represents higher-order relations so multi-step retrieval and reasoning stop feeling like a pile of disconnected sticky notes →read the paper 🌟 Valori: A Deterministic Memory Substrate for AI Systems
Enforce bit-identical memory states and retrieval across hardware by replacing float-based memory ops with fixed-point arithmetic and replayable state transitions for auditability →read the paper End-to-End Test-Time Training for Long Context
Compress what the model reads into its weights by continuing next-token learning at test time (with meta-learned initialization) to get long-context benefits with constant-latency inference →read the paper AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Synthesize how biological memory maps onto agent memory pipelines by comparing taxonomies, management lifecycles, benchmarks, and security concerns to guide practical system design →read the paper
|
Make agents more principled and more capable in the wild |
Nested Browser-Use Learning for Agentic Information Seeking
Enable deep information seeking through a minimal browser-action framework that separates control from exploration so agents can browse real pages without drowning in verbosity →read the paper Monadic Context Engineering
Formalize agent workflows as composable computational contexts using monads and related abstractions to handle state, errors, and concurrency without duct-taping imperative pipelines →read the paper 🌟 Training AI Co-Scientists Using Rubric Rewards (by Meta SuperIntelligence)
Train research-plan generators by extracting goals and rubrics from papers and using self-grading RL to improve constraint-following plans without relying on constant human scoring →read the paper
|
Make systems-level performance and portability real |
|
|
That’s all for today. Thank you for reading! Please send this newsletter to colleagues if it can help them enhance their understanding of AI and stay ahead of the curve. |
How did you like it? |
|
|