How to Avoid AI Code Slop
- Gregor Ojstersek and Ankit Jain from Engineering Leadership <gregorojstersek@substack.com>
- Hidden Recipient <hidden@emailshot.io>
Hey, Gregor here 👋 This is a free edition of the Engineering Leadership newsletter. Every week, I share 2 articles → Wednesday’s paid edition and Sunday’s free edition, with a goal to make you a great engineering leader! Here are some of the recent popular paid articles you might have missed: Additionally, I am hosting a live event in San Francisco on May 26th! It’s a free-to-join event, but there is a limited number of spots available, so make sure to register for the event while the spots are still available. How to Avoid AI Code SlopAI can generate code faster than ever, but it can also scale technical debt faster than ever! Learn the practical strategies to optimize the AI-generated output.
This week’s newsletter is sponsored by Larridin, an AI-native developer intelligence platform. Measure AI’s impact on engineering. Claude writes code 10x faster than a human. So why is engineering productivity up 20%, not 200%?
Engineers spend only 30-40% of their time actually coding. The rest goes to deployments, sprint planning, admin overhead, support questions, design reviews, incident response, and everything in between. Until now, we’ve had no way to map and measure where that invisible work actually goes. Larridin changes that. Mapping how engineering work flows across your org, surfacing the blockers and friction that drag on productivity, and showing you exactly what to fix. Larridin delivers complete 360° developer intelligence for AI-native engineering teams. From traditional developer productivity metrics to AI-era measures like Agent Effectiveness scores. Thanks to Larridin for sponsoring this newsletter, let’s get back to this week’s thought! IntroIn a previous article, I mentioned that code review is the new bottleneck for engineering teams. The reason is that these days, we are able to generate code faster than ever with AI. But the problem is that we can’t review the code fast enough, so the review process is the new bottleneck. And for that reason, a lot of teams are trying to find the right balance between these 2 options:
Lucky for us, Ankit Jain, CEO, Aviator, is our guest author for today’s article. He will be sharing his recommended solution. Let’s introduce our guest author and get started. Introducing Ankit JainAnkit is a cofounder and CEO of Aviator. Previously, he led engineering teams at Sunshine, Homejoy, and Shippo, and was also an engineer at Google and Adobe.
He also leads The Hangar, a community of senior DevOps and senior software engineers focused on developer experience. Today, he is sharing with us his take on how to avoid bad AI-generated code output, e.g., “AI code slop”. Over to you, Ankit! Code review process is not made for the AI-eraThis article is a follow-up to How to Kill the Code Review, which argued that traditional code review is no longer a viable quality gate in an AI-accelerated software development life cycle. The natural next question is, if not code review, then what? What should be the alternative? This article is the practical answer. Velocity charts look great. PRs are merging faster. If you only look at the code written, the numbers tell a story of AI accelerating output. But behind those metrics, engineering teams are accumulating a new kind of technical debt.
I am not saying engineering teams should go from reviewing every line of code to nothing. I’m advocating for moving the approval gates upstream to prevent what I call the “AI slop” code. Code that compiles, passes basic checks, and looks plausible but is subtly wrong. Now, let me share in more detail where AI-generated code goes wrong, even without “looking wrong”. 6 ways AI code goes wrong without looking wrong
The most dangerous variety. The code reads right and has correct syntax, but the logic is wrong. These bugs are difficult to catch in review because they require understanding what the code was supposed to do, not just what it does.
AI models are trained on vast bodies of code that include enterprise patterns, framework abstractions, and production-hardened architectures.
Asked to solve a problem that genuinely needs 15 lines, a model may produce a 200-line abstraction layer that anticipates a generality nobody asked for.
Models generate good generic code, not code that fits your system. Your repo has conventions around naming, error handling, logging patterns, and module boundaries. AI frequently ignores them, not because it can’t learn them, but because it hasn’t been told about them in the prompt.
Models confidently invoke methods that don’t exist, reference config options that were removed two versions ago, or call internal APIs that aren’t accessible in the current service context. These errors are sometimes caught immediately, and sometimes only in production.
Excessive try-catch blocks, silent error absorption, redundant logging. The code handles failure gracefully in the sense that it swallows it silently, making debugging substantially harder.
Copies patterns without understanding why, like retry logic in a context where retries make no sense. Circuit breakers for calls that are always synchronous. Error handling that looks thorough but doesn’t map to actual failure modes. The pattern is there; the reasoning behind it is not.
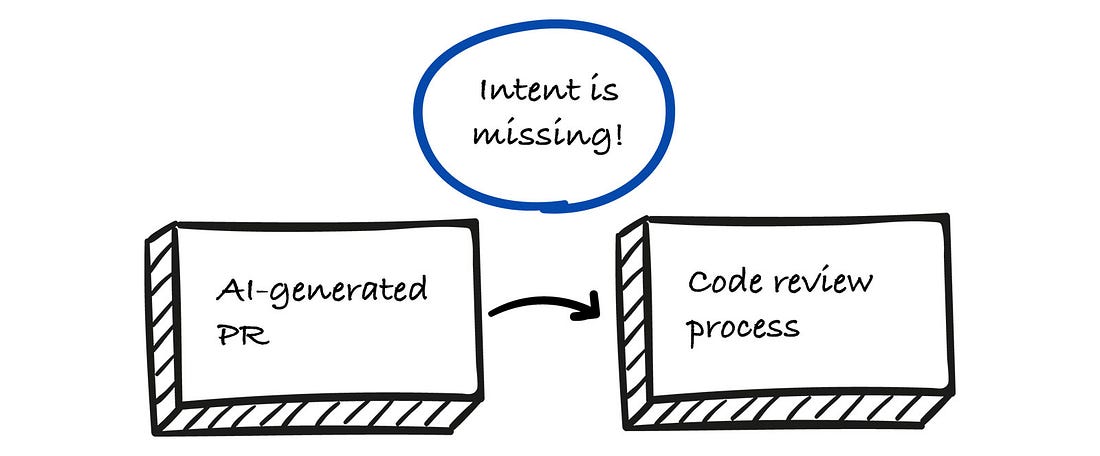
Why existing processes are not enoughCode review was designed for a different world. AI-generated PRs are different in kind, not just in scale. When a human writes code, intent travels with the author through the review process. They can explain the tradeoffs they considered, the alternatives they rejected, and the constraints they worked within. Even unwritten, that context is accessible. When AI writes code, intent may exist in a prompt that was never saved, a ticket that doesn’t capture the decision-making, or only in the engineer’s head. The implementation is preserved; the reasoning behind it is not. Tests catch less than we assume. Automated testing is necessary but not sufficient. Tests verify behavior within the scope of what the test author thought to test. AI-generated code introduces failure modes that are, by definition, unanticipated because if the engineer had anticipated them, they would have specified them in the prompt.
The missing ingredient: Intent
The concept of formalizing intent before implementation isn’t new. Behavior-Driven Development, Test-Driven Development, and Design by Contract all attempt to define behavior in a structured, human-readable form before any code is written. These approaches were often perceived as overhead. Under delivery pressure, they got skipped. AI makes them practical in a way they were never before. AI can help generate structured acceptance criteria, specs, and contract-like descriptions from a brief. It can also verify output against them. The overhead objection disappears when the spec itself is AI-assisted. We tested intent-driven verification on a real featureAt Aviator, we recently ran an experiment to test the intent-driven verification approach. With the main question we wanted to answer:
The team implemented a medium-scoped, full-stack feature. A hierarchical, per-repository configuration system, with zero manually written application code. Everything was guided by a spec reviewed and agreed upon by the team before a single line was generated. It spanned the full stack, including a database model and migration for config history, a schema/validation layer, a resolution engine that merges repo and global configs, a GraphQL API (types + mutation) for reading and updating configs, integration of the resolved config into all runtime subsystems (sandbox provisioning, CI handling, code generation, chat processing, persona selection), and a frontend settings page with a config editor, change history view, and source indicators showing where each setting originates. The kind of feature that, done conventionally, would generate dozens of review comments across multiple PRs. Writing the specThe spec was generated collaboratively: a scaffolding PRD was fed to Claude Code, which was instructed to ask clarifying questions that were answered synchronously by the team. The resulting spec was reviewed at two levels.
Specific UI component choices, input validation requirements, performance strategies like Redis caching for config lookups. These are the kinds of concerns that normally surface during code review, not spec review.
The team caught a missing UX requirement, questioned whether a persona’s feature was well-defined enough to include, and flagged places where the spec text was out of sync with the actual design (e.g., referencing a table that didn’t exist). These are decisions that, if deferred to post-implementation review, would require rework. The spec review took about 10 hours of engineering work across multiple engineers. It produced 14 acceptance criteria with 65 checkable items. It also produced a document that could serve as a document against which the code could be verified. Implementation and verificationWe used Claude Code to implement the spec. The agent decided to split the implementation into four phases:
The whole implementation consisted of around 6k lines of code, with 40% app code, 40% tests, and 20% GraphQL auto-generated files. It’s worth noting that no explicit instruction to write tests was given in the specification, which suggests the agent’s strategy for meeting the acceptance criteria was to write tests. A second agent then verified the 65 acceptance criteria against the resulting PRs. This took six minutes and produced a structured report with file references and explanations for each item:
A human doing the same verification thoroughly would have needed hours. What the code review caughtHuman reviewers left an average of 10 comments per PR. Few bugs were found, with the major one being a stale editor state. Code review caught convention-level issues such as import placement, enum duplication, and naming patterns. This was an expected outcome. Spec review catches design-level issues like missing requirements, underspecified features, and scope questions. Code review catches convention-level issues, the things that require familiarity with your specific codebase. Both layers are necessary because they catch different things. Five guardrails engineering teams can start using nowWe’re still learning how to write specs that are precise enough for agents to implement reliably but flexible enough that the team doesn’t spend more time specifying than they would have spent coding.
If we think about writing a spec simply as writing a JIRA ticket, that stress can go away. For a simple issue, a single-line intent or what you’d write in a ticket could be a sufficient spec detail, and acceptance criteria can be generated by AI. Our experiment worked well enough to change how we think about verifying AI code and preventing code slop. The following practices are not a complete methodology. They’re a set of concrete interventions that teams can adopt incrementally, starting where they have the most pain.
Large, open-ended prompts produce the most slop. ‘Build this feature’ hands the AI too much latitude. Well-scoped tasks with clear boundaries: a specific function, a defined API surface, or a constrained refactor, produce way better output and are significantly easier to verify. This is counterintuitive for teams that see AI’s value in handling large tasks. The value is there, but it works better when large tasks are decomposed into smaller, well-specified subtasks with explicit checkpoints between them. It’s no different from how we humans work better.
Before any code is generated, the intent should be written down in a form that can be reviewed and approved. This doesn’t require a formal methodology. It requires the habit of documenting the what before generating the how. Acceptance criteria can also be written by AI. Intent is really hidden in the prompt conversation that the user is having with AI (the decision tree) or the details a user may be adding in the ticket. At the more rigorous end, it means BDD-style specs or contract-like descriptions that can be used to verify output. The exact format matters less than the discipline of capturing intent explicitly. Again, I’m not trying to add overhead and invent new documents to write. We already do a pretty good job of expressing intent when prompting LLMs. In practice, that would most probably look like a lightweight spec template for AI-assisted work. Two to three sentences on scope, a list of acceptance criteria, and a note on what’s explicitly out of scope. Make it a PR requirement. That, again, can be generated by AI.
For any AI-assisted task above a certain complexity threshold, require spec approval before code generation begins.
When a design decision is caught in a spec review, fixing it is a sentence change. When it’s caught in code review, it may require significant rework. Teams that shift review earlier, approving specs before generating code, front-load the high-value decisions and leave code review to do what it’s actually good at: catching implementation-level issues.
Tests, linting, and type checks catch surface-level slop, and you should absolutely not skip those. As I said in my piece, trust is layered when it comes to AI code. We stack imperfect filters until nothing comes through.
Every codebase has patterns that AI consistently gets wrong. Maybe it’s a specific error-handling convention, a naming pattern, a module boundary that gets violated, or a library the AI prefers that you’ve deprecated. These are knowable and preventable. A slop register serves two purposes: feeding these patterns back into prompts (to prevent them from occurring) and informing CI checks (to catch them when they do). You don’t need the full workflow to see resultsThe most common pushback against spec-first workflows is that they’re slower. Writing specs takes time. Getting them reviewed and approved takes time. And engineers who are already productive with AI tooling don’t want to slow down. It may seem that this intent-driven verification adds process, but we are just changing the ways of working that we’re used to. The tools aren’t ready. The organizational structures aren’t ready. We are in transition. If your team is early in this process, the most valuable first step is usually the simplest one: require capturing the intent from prompts for any AI-assisted task above a defined complexity threshold. The format doesn’t have to be perfect and rigidly defined at first. A few sentences on scope, a short list of acceptance criteria, and a note on what’s out of scope. From there, introduce a spec review as a step before code generation. Add the slop register. Build toward automated verification against acceptance criteria. The full workflow takes time to establish. But each step in that direction improves the signal-to-noise ratio of what ends up in the codebase, and makes the AI investment return what it’s supposed to return. Last wordsSpecial thanks to Ankit for sharing his insights on this important topic with us! Make sure to check out Aviator, they are building a lot of cool stuff there, highly relevant for building engineering teams in the AI era. Liked this article? Make sure to 💙 click the like button. Feedback or addition? Make sure to 💬 comment. Know someone that would find this helpful? Make sure to 🔁 share this post. Whenever you are ready, here is how I can help you further
Get in touchYou can find me on LinkedIn, X, YouTube, Bluesky, Instagram or Threads. If you wish to make a request on particular topic you would like to read, you can send me an email to info@gregorojstersek.com. This newsletter is funded by paid subscriptions from readers like yourself. If you aren’t already, consider becoming a paid subscriber to receive the full experience! You are more than welcome to find whatever interests you here and try it out in your particular case. Let me know how it went! Topics are normally about all things engineering related, leadership, management, developing scalable products, building teams etc.
You're currently a free subscriber to Engineering Leadership. For the full experience, upgrade your subscription.
|


Similar newsletters
There are other similar shared emails that you might be interested in: