Why your AI product needs a different development lifecycle
Why your AI product needs a different development lifecycleIntroducing the Continuous Calibration/Continuous Development (CC/CD) framework👋 Welcome to a 🔒 paid edition 🔒 of my weekly newsletter. Each week, I tackle reader questions about building product, driving growth, and accelerating your career. For more: Lenny’s Podcast | How I AI | Lennybot | Lenny’s Reads | Courses P.S. Annual subscribers get a free year of 15+ premium products: Lovable, Replit, Bolt, n8n, Wispr Flow, Descript, Linear, Gamma, Superhuman, Warp, Granola, Perplexity, Raycast, Magic Patterns, Mobbin, and ChatPRD (while supplies last). Subscribe now. In this AI era, tech leaders need to re-evaluate every single industry best practice for building great products. AI products are just built differently. The teams that realize that and adjust the most quickly will have a huge advantage. Based on their experience leading over 50 AI implementations at companies including OpenAI, Google, Amazon, Databricks, and Kumo, Aishwarya Reganti and Kiriti Badam have developed the Continuous Calibration/Continuous Development (CC/CD) framework to specifically address the unique challenges of shipping great AI-powered products. In this post, they’re sharing it for the first time with you. For more from Aish and Kiriti, check out their popular Maven course and their upcoming free lightning talk that explores this topic in depth. You can also listen to this post in convenient podcast form: Spotify / Apple / YouTube
If you’re a product manager or builder shipping AI features or products, you’ve probably felt this: Your company is under pressure to launch something with AI. A promising idea takes shape. The team nails the demo, the early reviews look good, and stakeholders are excited. You push hard to ship it to production. Then things start to break. You’re deep in the weeds, trying to figure out what went wrong. But the issues are tangled and hard to trace, and nothing points to a single fix. Suddenly your entire product approach feels shaky. We’ve seen this play out again and again. Over the past few years, we’ve helped over 50 companies design, ship, and scale AI-powered autonomous systems with thousands of customers. Across all of these experiences, we’ve seen a common pitfall: people overlook the fact that AI systems fundamentally break the assumptions of traditional software products. You can’t build AI products like other products, for two reasons:
When companies don’t recognize these differences, their AI products face ripple effects like unexpected failures and poor decision-making. We’ve seen so many teams experience the painful shift from an impressive demo to a system that can’t scale or sustain. And along the way, user trust in the product quietly erodes. After seeing this pattern play out many times, we developed a new framework for the AI product development lifecycle, based on what we’ve seen in successful deployments. It’s designed to recognize the uniqueness of AI systems and help you build more intentional, stable, and trustworthy products. By the end of this post, you should be able to map your own product to this framework and have a better sense of how to start, where to focus, and how to scale safely. Let’s walk through the ways that building AI products is different from traditional software. 1. AI products are inherently non-deterministicTraditional software behaves more or less predictably. Users interact in known ways: clicking buttons, submitting forms, triggering API calls. You write logic that maps those inputs to outcomes. If something breaks, it’s usually a code issue, and you can trace it back. AI systems behave differently. They introduce non-determinism on both ends: in other words, there’s unpredictability in how users engage and how the system responds. First, the user interaction surface is far less deterministic. Instead of structured triggers like button clicks, users interact through open-ended prompts, voice commands, or other natural inputs. These are harder to validate, easier to misinterpret, and vary widely in how users express intent. Second, the system’s behavior is inherently non-deterministic. AI models are trained to generate plausible responses based on patterns, not to follow fixed rules. The same request can produce different results depending on phrasing, context, or even a different model. This fundamentally changes how you build and ship. You’re no longer designing for a predictable user flow. You’re designing for likely behavior—both from the user and the product—not guaranteed behavior. Your development process needs to account for that uncertainty from the start, continuously calibrating between what you expect and what shows up in the real world. 2. Every AI product negotiates a tradeoff between agency and controlThere’s another layer that makes AI systems different, and it’s one we rarely had to think about before with traditional software products: agency. Agency, in this context, is the AI system’s ability to take actions, make decisions, or carry out tasks on behalf of the user (which is where the term “AI agent” comes from). Think:
Unlike traditional tools, AI systems are built to act with varying levels of autonomy. But here’s the part people often overlook: Every time you give an AI system more agency, you give up some control. So there’s always an agency-control tradeoff at play. And that tradeoff matters (a lot!). If your system suggests a response, you can still override it. If it sends the response automatically, you’d better be sure it’s right. The mistake most teams make is jumping to full agency before they’ve tested what happens when the system gets it wrong. If you haven’t tested how the system behaves under high control, you’re not ready to give it high agency. And if you hand over too much agency without the system earning it first, you may lose visibility into the system, and the trust of your users. What’s more, you’re stuck debugging a large, complicated system that has taken actions you can’t trace, for reasons you’ve lost insight into, so you don’t even know what to change. Which brings us to the core framework we’ve developed to help teams navigate these distinctions. We call it CC/CD: Continuous Calibration/Continuous Development. The name is a reference to Continuous Integration/Continuous Deployment (CI/CD), but, unlike its namesake, it’s meant for systems where behavior is non-deterministic and agency needs to be earned. The Continuous Calibration/Continuous Development framework
Just like in traditional software, AI products move through phases toward an end goal. But building AI requires you to account for two things we mentioned earlier: non-determinism and the agency-control tradeoff. The CC/CD framework is designed to work around these two realities by:
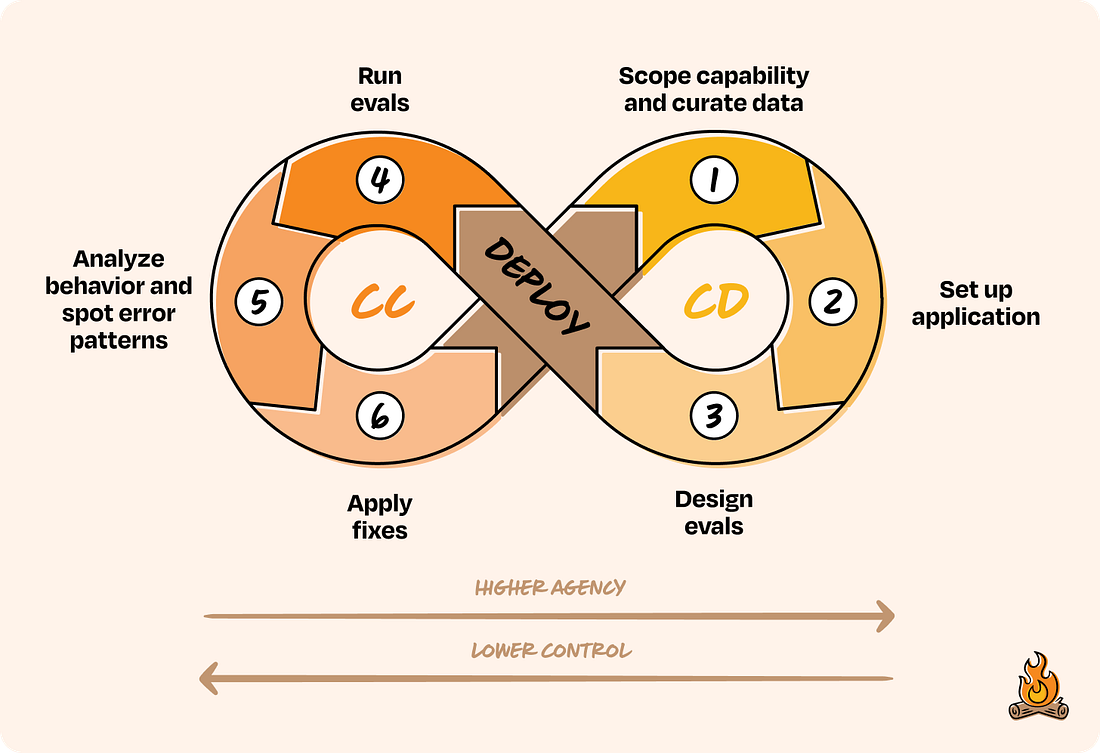
In our framework, product builders work in a continuous loop of development (CD) and calibration (CC). During development, you scope the problem, design the architecture, and set up evaluations to keep non-determinism in check. You start with features that are low-agency and high-control, then gradually move up as the system proves it can handle more. Then you deploy, not as a finish line but as a transition into the next phase. Once you’ve deployed, you enter the calibration loop, where you observe real behavior, figure out what broke, and make targeted improvements. With every cycle, the system earns a bit more agency. Over time, this loop turns into a flywheel, tightening feedback, building trust, and making the product stronger with each version.
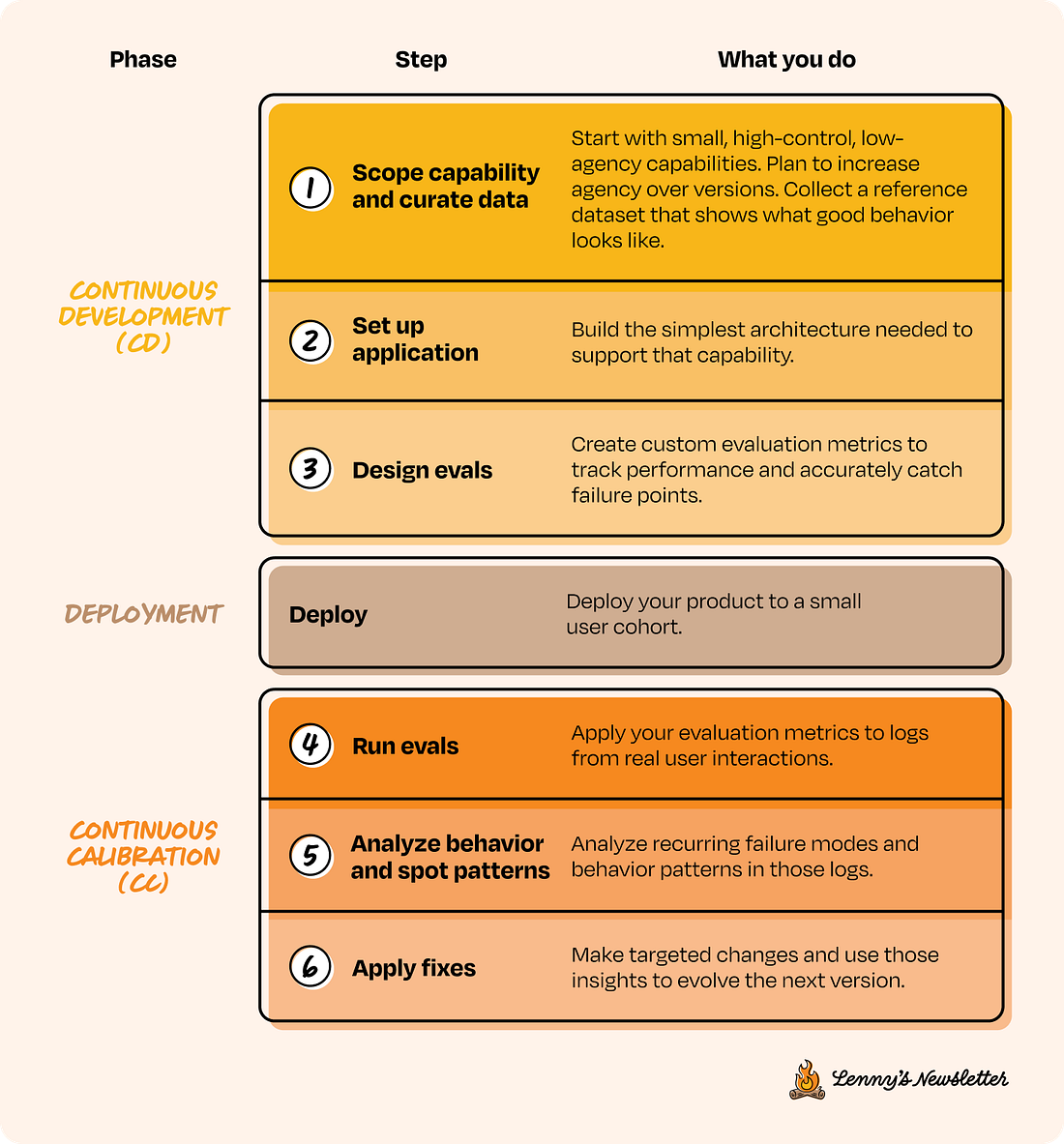
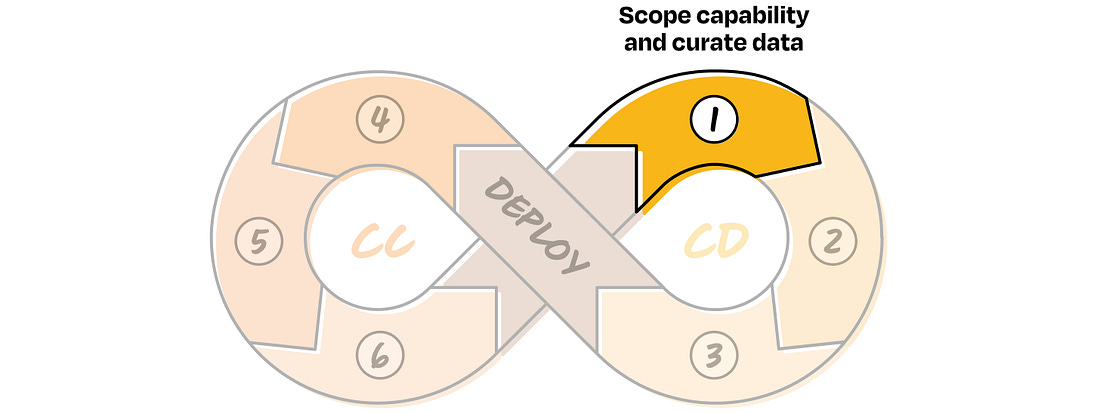
Let’s go deeper into each step of the CC/CD loop, what it looks like, why it matters, and how to do it well. The first three steps make up the Continuous Development side of the loop: scoping the capability, setting up the application, and designing evals. CD 1. Scope capability and curate data
Let’s say you have a big product idea and you’ve already done your research. It’s clear that AI is the right approach. In traditional software development, you’d typically plan for v1, v2, v3 of the new product based on feature depth or user needs. With AI systems, the versioning still applies, but the lens shifts.
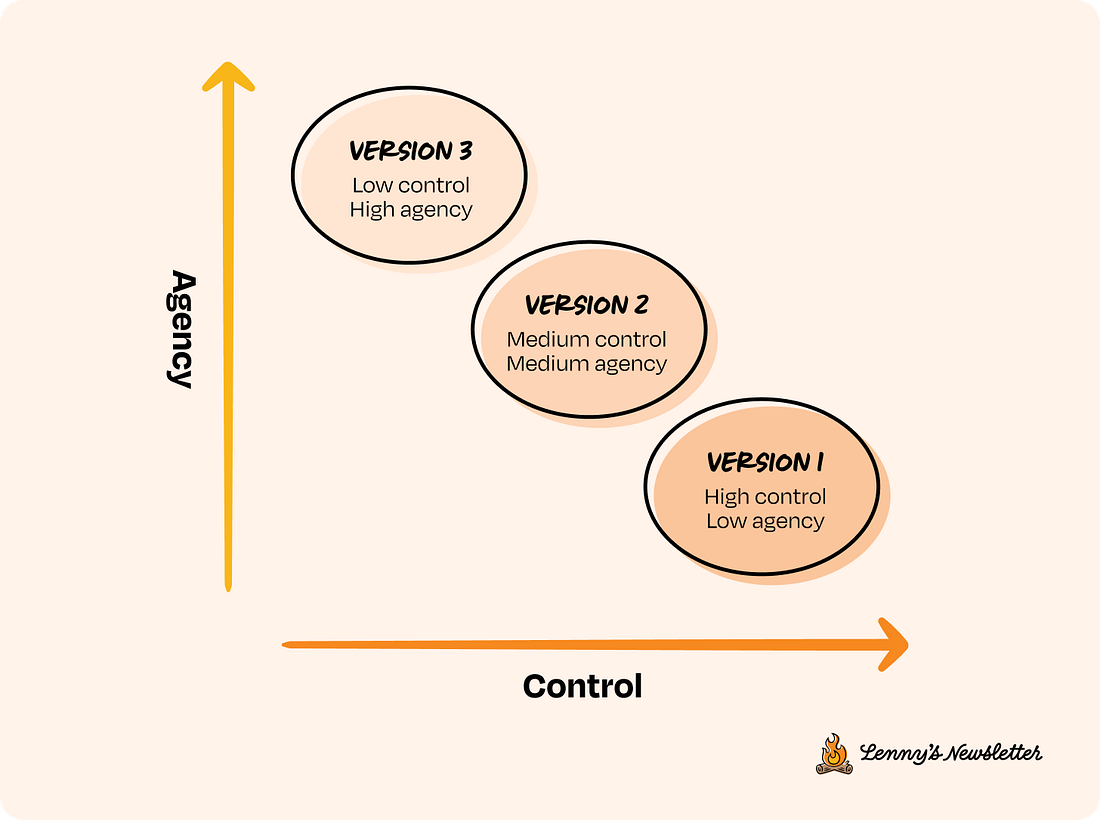
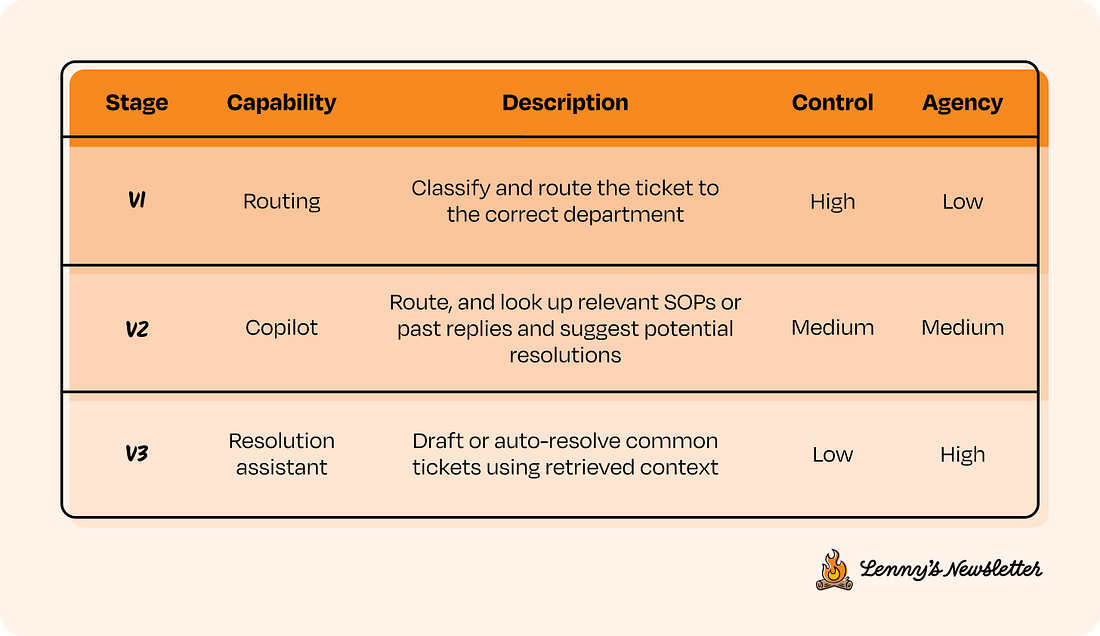
Here, each version is defined by how much agency the system has and how much control you’re willing to give up. So instead of thinking in terms of feature sets, you scope capabilities. Start by identifying a set of features that are high control and low agency (version 1 in the image above). These should be small, testable, and easy to observe. From there, think about how those capabilities can evolve over time by gradually increasing agency, one version at a time. The goal is to break down a lofty end state into early behaviors that you can evaluate, iterate on, and build upward from. For instance, if your end goal is to automate customer support in your company, a high-control way to start would be to scope v1 (version 1) as simply routing tickets to the right department, then move to v2 where the system suggests possible resolutions, and only in v3 allow it to auto-resolve with human fallback. Remember, this is just one approach. What it looks like in practice will depend on your product, but the process tends to be consistent: Start with simple decisions that are easy to verify and easy for humans to override. Then, as you progress through the CC/CD loop, gradually layer in more autonomy with each version. How long you stay in each version depends entirely on how much behavioral signal you’re seeing. You’re optimizing for understanding how your AI behaves under real-world noise and variation. Here are a couple more examples: Marketing assistant
Coding assistant
If you’ve followed how tools like GitHub Copilot or Cursor evolved, this is exactly the playbook they used. Most users only see the current version, but the underlying system climbed that ladder gradually. First completions, then blocks, then PRs, with each step earned through usage, feedback, and iteration. Now, because user behavior is non-deterministic, you’ll need to build a reference for what expected behavior looks like and how your AI system should respond. That’s where data comes in. Data helps break the cold start and gives you something concrete to evaluate against. We call this the reference dataset. In the customer support automation example, for the routing version (v1), your reference dataset might include:
You can pull this from past logs if available, or generate examples based on how your product is expected to work. This dataset helps you evaluate system performance and also tells you what context your assistant needs in order to perform reliably. Since most products start cold, aim to gather at least 20 to 100 examples up front. We’ll continue using the customer support example to walk through the next steps in the CC/CD loop. Imagine you’re building toward a fully autonomous support system for a company. Below are the versions we’ll reference, along with their corresponding agency and control levels. We’ll refer to v1, v2, and v3 throughout the rest of the post.
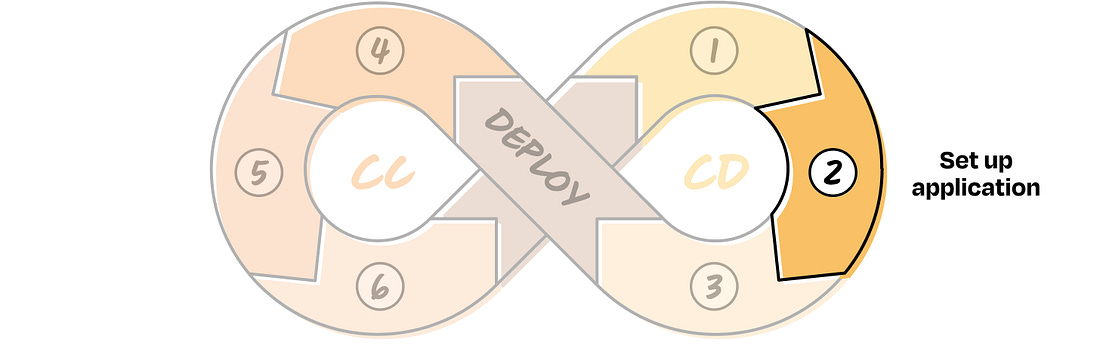
CD 2. Set up application
Most people skip step 1 and jump into the setup phase too early, getting lost in implementation choices and overthinking which components are needed. But if you’ve scoped your capability properly in step 1, looked at enough examples, and curated a solid reference dataset, setting up the application should be fairly straightforward. You already know what the system needs to do, have a sense of what users are likely to throw at it, and understand what a good response looks like. Now it’s just about wiring together the simplest version that gives you a useful signal. There’s a famous saying in software, for a reason: “Premature optimization is the root of all evil.” It applies here too. Don’t overengineer. Don’t over-optimize. Not at this stage. Just don’t. Build only what’s needed for your current version. Make the system measurable and iterable by setting up logs to capture what the system sees from the user, what it returns, and how people interact with it. This will form the basis of your live interaction dataset and help you improve the system over time. We won’t go deep into implementation here, but if you’re exposing this to end users, make sure the basics like guardrails and compliance are in place. One more important point: When setting up the application, make sure control can be handed back to humans seamlessly when needed. We’ll refer to these as control handoffs. For example, in the customer support v1, if a ticket is misrouted, the receiving agent (the point of contact for that department) should be able to reroute it easily. Since that correction is logged, it not only helps improve the system over time but also preserves the user experience. Thinking about control handoffs from the start is key to building trust and keeping things recoverable. CD 3. Design evals
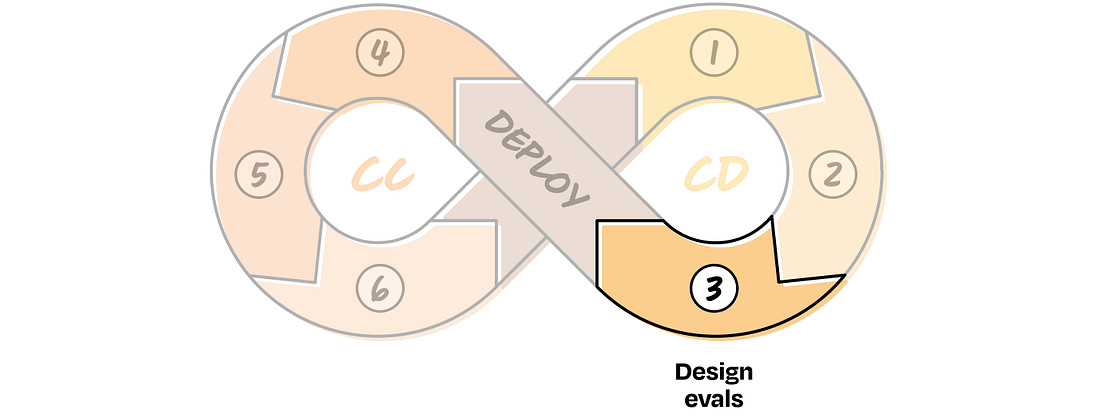
This is the part that usually takes a bit of thought. Before shipping anything, you need to define how you’ll measure whether the system is doing what you expect and whether it’s ready for the next step. You do this using evaluation metrics (evals, for short). So, what are evals?... Subscribe to Lenny's Newsletter to unlock the rest.Become a paying subscriber of Lenny's Newsletter to get access to this post and other subscriber-only content. A subscription gets you:
|

Similar newsletters
There are other similar shared emails that you might be interested in: