This Week in Turing Post: | Wednesday / AI 101 series: What's new in World Models: Code WM by Meta, PSI, and more Friday / AI Unicorn series continues
| Our news digest is always free. Upgrade to receive our deep dives in full, directly into your inbox. | |
|
| Topic One: AI in Science with incredible pedigree | This might be one of the most important events this year for AI and its practical success. The biggest VC muscles are betting on the bitter lesson taken literally – and on science as the next great RL environment. Startups Periodic Labs and Axiom Math are two expressions of that idea at different scales, one in physics and one in formal reasoning. Both push AI out of the text box and into domains where truth is verifiable, where hypotheses can fail, and where every iteration generates new data that no one has ever seen before. AI is truly getting real in science. | At Periodic Labs, the scientific loop happens in the physical world. Founded by Liam Fedus and Ekin Dogus Cubuk, the company builds systems where AI models control robotic laboratories, run experiments, and learn from the outcomes. Fedus and Cubuk have rare depth across science and machine learning. Fedus previously led post-training research at OpenAI, helping to shape ChatGPT, while Cubuk co-authored DeepMind’s GNoME, which discovered millions of new crystalline materials. Their $300 million backing from a16z, Felicis, NVIDIA Ventures, Accel, DST, Jeff Bezos, Eric Schmidt, and Elad Gil gives them resources to connect machine intelligence with automated chemistry. Early projects focus on practical goals: finding new superconductors, efficient materials, and heat-resistant semiconductors. Each advance strengthens the hardware foundation of computing itself – a feedback loop between intelligence and the energy that sustains it. Again, this is big. | Axiom Math applies the same principle on an abstract plane. 24-year old Carina Hong, a Stanford dropout with MIT and Oxford credentials, gathers Meta’s top FAIR mathematicians to build an AI mathematician that proposes, proves, and verifies theorems in a fully self-consistent world of logic. It’s an autonomous discovery engine for formal truth, one that treats reasoning as an experimental process. | What’s striking about both is their shared intent: to turn AI from a mimic into an explorer. The internet was the training ground. Are reality and proof the next ones? How far can it catapult us? We are watching these two projects very closely. | Topic Two: What does Karpathy sees? | The conversation between Richard Sutton and Dwarkesh Patel was important at least because it revived the old question of what learning really is – and reminded many of the history behind reinforcement learning. It also made Dwarkesh pause and examine his own stance more carefully (I was surprised to see him in my comments, and I appreciated that reflection). Once a month we summarize what Andrej Karpathy said, and this time his main post was about that same conversation between Patel and Sutton. | Karpathy’s reflection, prompted by Sutton’s remarks, turns into an examination of the field itself. He agrees with Sutton’s call for learning through direct interaction but points out that nature’s “pretraining” took billions of years. Internet-scale data, he suggests, is our shortcut – a way to build a foundation before systems can learn continuously from the world. | He ends with a modest metaphor that spread quickly online: LLMs as ghosts, not animals – digital reflections of human knowledge rather than living learners. They don’t evolve, but they can still act and create. “Ghosts:animals :: planes:birds,” Karpathy writes. Well, Andrej always comes up with some interesting terms and memes that set internet on fire. | | 🤝 Meet Me at NVIDIA GTC DC + Win a Jetson Orin Nano Super | Folks, let’s meet up in Washington. I will be going to NVIDIA GTC on October 27–29 in Washington, DC to dive into the sessions I’m most curious about – from physical AI for robotics to agentic developer tools and the future of AI infrastructure. There are an enormous number of interesting talks and panels, but I’m especially excited about Accelerating the Physical AI Era With Digital Twins and Real-Time Simulation and Advancing U.S. Quantum Leadership. Join me there! If you can’t make it in person, you can still be part of it: register to watch Jensen Huang’s keynote live. But it will be cool if we can chat in person. | | And because learning is better shared, I’m running a Jetson Orin Nano Super giveaway tied to the event. Just share a screenshot of you watching the keynote plus one learning you took away, and you’ll be entered. I’ll feature some of your notes and pick a winner after GTC. Follow our twitter for more details about the giveaway. | | | Links from the editorial: | | | | Curated Collections – MCP servers | | | News from The Usual Suspects © | |  | Patrick Collison @patrickc |  |
| |
We have three cool announcements today: (1) @OpenAI is launching commerce in ChatGPT. Their new Instant Checkout is powered by @stripe.
(2) We're releasing the Agentic Commerce Protocol, codeveloped by Stripe and OpenAI.
(3) @stripe is launching an API for agentic payments, | | | 5:33 PM • Sep 29, 2025 | | | | | | 6.03K Likes 554 Retweets | 258 Replies |
|
| Plus, you might have heard OpenAI launched Sora 2. We will be covering that in the video this week. Hit reply if you still need an invite. Perplexity takes a hit on Google making its AI-powered browser Comet free. Microsoft | The Agent Awakens Microsoft debuts its Agent Framework – a unified, open-source SDK merging AutoGen and Semantic Kernel for building enterprise-ready multi-agent AI systems. Backed by Azure AI Foundry, it simplifies orchestration, boosts observability, and plays well with any API. Private preview of multi-agent workflows adds long-running stateful processes; OpenTelemetry integration brings cross-framework tracing; and Voice Live API is now GA, enabling real-time speech-to-speech agents. With Responsible AI tools like prompt shields and PII detection, Microsoft keeping agents in check. Google DeepMind | Proof by LLM Google DeepMind’s AlphaEvolve is pushing boundaries in theoretical computer science, not by writing full proofs, but by discovering intricate combinatorial structures that can be verified. The AI-coded agents helped tighten approximation bounds for MAX-4-CUT and explored average-case hardness using Ramanujan graphs.
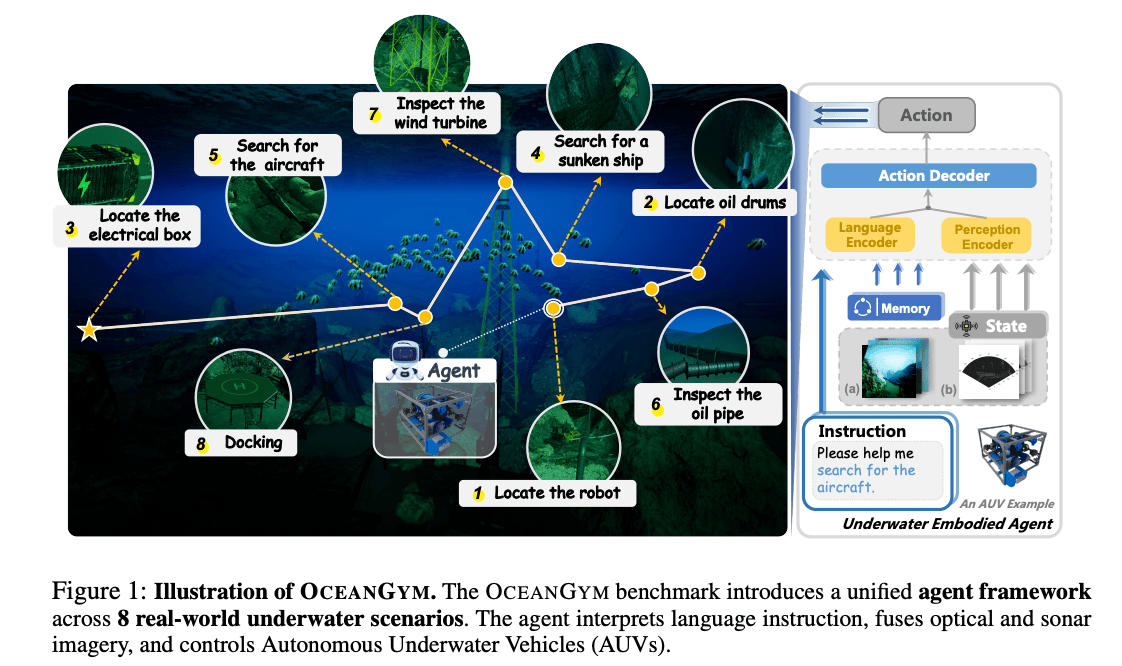
| | | A very interesting benchmark | | Oceangym: A benchmark environment for underwater embodied agents
Researchers from Zhejiang University and the National University of Singapore developed OceanGym, the first high-fidelity simulation platform for evaluating LLM-driven underwater embodied agents. Spanning 800×800m, it features 8 realistic tasks, including shipwreck search and pipeline inspection, under both shallow (50m) and deep (500m) conditions. In deep water, agents’ perception accuracy dropped below 30% and decision task success averaged 14.8%, far below human performance (69.6%), revealing challenges in sonar comprehension, memory, and sequential decision-making. | Models to pay attention to | Claude Sonnet 4.5 Anthropic released Claude Sonnet 4.5, which leads on SWE-bench Verified with 77.2% (82.0% under high compute) and OSWorld at 61.4%, up from 42.2%. It excels in reasoning, math, and domain knowledge across finance, law, medicine, and STEM. New features include code checkpoints, a VS Code extension, a Claude Agent SDK, and file creation in chat. Alignment improved with ASL-3 safety, reducing sycophancy and deception significantly →read their blog IBM Granite 4.0
Researchers from IBM released a family of hybrid Mamba-transformer LLMs optimized for enterprise use. Models include H-Small (32B total/9B active), H-Tiny (7B/1B), and H-Micro (3B). They achieve over 70% RAM reduction vs transformers and maintain fast inference at long context lengths (up to 128K tokens). Granite 4.0 is ISO 42001-certified, cryptographically signed, excels on IFEval and BFCLv3 benchmarks, and supports deployment across diverse platforms and hardware →read the paper Llava-Onevision-1.5
Researchers from the LLaVA-OneVision community developed a fully open-source LLM-based multimodal framework trained with only $16,000. It uses an 85M concept-balanced dataset and a 22M instruction set. The 8B model outperforms Qwen2.5-VL-7B on 18/27 benchmarks; the 4B model beats Qwen2.5-VL-3B on all 27. It integrates RICE-ViT for enhanced OCR and region-level understanding and achieves state-of-the-art results across VQA, reasoning, and chart tasks →read the paper Sana-video
Researchers from NVIDIA, HKU, MIT, THU, PKU, KAUST developed a 2B-parameter diffusion model that generates 720p, minute-long videos efficiently using linear attention and a constant-memory KV cache. It requires only 12 training days on 64 H100 GPUs—1% the cost of MovieGen—and generates a 5s 720p video in 36s, 16× faster than Wan2.1-1.3B. SANA-Video achieves 84.05 VBench total score and state-of-the-art semantic alignment, supporting T2V, I2V, and T2I tasks with strong motion consistency and RTX 5090 deployment via NVFP4 quantization →read the paper ModernVBERT
Researchers from Illuin Technology, EPFL, and CentraleSupélec developed a 250M-parameter vision–language encoder optimized for document retrieval. Using bidirectional attention, MLM objectives, and high-resolution (2048px) inputs, it outperforms models up to 10× larger. Its ColModernVBERT variant achieves 68.6 nDCG@5 on ViDoRe with CPU latency of 32ms. Key innovations include a constant-memory early fusion design, late interaction matching, and scaled contrastive training with mixed text–image and text-only data, proving efficient and accurate document-level retrieval →read the paper
| | The freshest research papers, categorized for your convenience | We organize research papers by goal-oriented or functional categories to make it easier to explore related developments and compare approaches. As always, papers we particularly recommend are marked with 🌟 | Special attention to this paper → | 🌟 The Dragon Hatchling (by Pathway) introduces a new architecture for language models that aims to bridge the gap between how transformers work and how biological brains function. It’s based on local neuron interactions in a sparse, scale-free graph. BDH models neurons as particles linked by dynamic synapses updated via Hebbian learning, replacing global attention with local edge reweighting. Its GPU-efficient variant, BDH-GPU, uses linear attention and sparse positive activations, matching GPT2-like performance up to 1B parameters. BDH exhibits interpretable neuron behavior, emergent modularity, and scale-free structure, aligning neural reasoning with biological plausibility. →read the paper
| Reinforcement Learning for Reasoning and Agentic Behavior | Papers that rethink how LLMs explore, reason, or align using reinforcement learning, verifiable rewards, or adaptive exploration. | 🌟 RLP: Reinforcement as a Pretraining Objective (by Nvidia) – bring exploration earlier into pretraining by rewarding reasoning chains that increase information gain, bridging next-token prediction and RL reasoning. ->read the paper 🌟 BroRL: Scaling Reinforcement Learning via Broadened Exploration (Nvidia) – scale RLVR by massively increasing rollout diversity to revive training beyond saturation and achieve continuous gains. ->read the paper 🌟 DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search – embed MCTS inside RLVR training to expand reasoning exploration and beat brute-force scaling. ->read the paper 🌟EPO: Entropy-regularized Policy Optimization for LLM Agents – stabilize multi-turn RL by smoothing entropy across training phases to prevent exploration-exploitation collapse. ->read the paper 🌟 ExGRPO: Learning to Reason from Experience – reuse valuable RL rollouts based on correctness and entropy to stabilize reasoning improvements. ->read the paper Knapsack RL: Unlock Exploration via Optimizing Budget Allocation – treat exploration as a knapsack problem to allocate compute adaptively across tasks. ->read the paper 🌟 RLAD: Train LLMs to Discover Abstractions (by Carnegie, Stanford) – generate concise reasoning primitives with two-player RL that separates abstraction creation from solution generation. ->read the paper VERL: Beyond the Exploration-Exploitation Trade-off – shape rewards in hidden-state space to enhance exploration and exploitation simultaneously. ->read the paper TruthRL: Incentivize Truthful LLMs via Reinforcement Learning – reward truthfulness by distinguishing correct, hallucinated, and abstained responses to balance accuracy and honesty. ->read the paper FlowRL: Match Reward Distributions for LLM Reasoning – replace scalar reward maximization with full-distribution matching to promote diverse reasoning paths. ->read the paper Random Policy Valuation is Enough for LLM Reasoning – compute optimal actions from a random-policy Q-function, simplifying RLVR while improving diversity. ->read the paper Evolving Language Models without Labels – couple majority-vote stability with novelty rewards so unlabeled models can self-improve without supervision. ->read the paper From f(x) and g(x) to f(g(x)) – show that RL teaches genuinely new, compositional skills rather than reweighting old ones. ->read the paper 🌟 The Era of Real-World Human Interaction: RL from User Conversations Meta) – learn alignment directly from in-the-wild user dialogue using persona-conditioned rewards. ->read the paper Socratic-Zero: Bootstrap Reasoning via Data-Free Agent Co-evolution – co-evolve teacher, solver, and generator agents to create self-improving synthetic reasoning curricula. ->read the paper
| Architectures, Optimization & Training Mechanics | Research that rethinks model structure, optimizers, or training loops to improve efficiency, interpretability, and robustness. | 🌟 Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts – reuse prior reasoning as composable thought graphs to guide new problems, reducing tokens and latency while preserving accuracy. ->read the paper Sequential Diffusion Language Models – unify next-token and next-block prediction to make diffusion models KV-cache-compatible and efficient. ->read the paper 🌟 In Their Own Words: Reasoning Traces Tailored for Small Models Make Them Better Reasoners (by Yonsei University) – align teacher–student distillation by generating student-friendly reasoning traces through Reverse Speculative Decoding (RSD), where the teacher proposes and the student filters low-probability tokens, ensuring reasoning steps stay within the smaller model’s representational range. ->read the paper Thinking-Free Policy Initialization – discard explicit thought tokens during RLVR initialization to cut compute while keeping reasoning strength. ->read the paper 🌟 It Takes Two: Your GRPO is Secretly DPO (Mila) – reveal GRPO’s equivalence to DPO and show two-rollout training can match large-group stability. ->read the paper Muon Outperforms Adam in Tail-End Associative Memory Learning – explain Muon’s optimizer edge through better isotropy and balanced learning on heavy-tailed data. ->read the paper Fine-tuning Done Right in Model Editing – restore mini-batch fine-tuning for scalable, interference-free model editing up to 72B parameters. ->read the paper SINQ: Sinkhorn-Normalized Quantization – minimize matrix imbalance for calibration-free low-precision quantization below 4 bits. ->read the paper Interactive Training: Feedback-Driven Neural Network Optimization – enable humans or AI agents to steer training in real time through dynamic hyperparameter and data control. ->read the paper EasySteer: A Unified Framework for LLM Steering – provide a modular, high-speed infrastructure for manipulating hidden states to control behavior at inference. ->read the paper 🌟 Thinking Sparks!: Emergent Attention Heads in Reasoning Models (by Korea University) – analyze how post-training produces specialized attention heads that balance complex reasoning with simple accuracy. ->read the paper 🌟 Why Can’t Transformers Learn Multiplication? – reverse-engineer an implicit-CoT model to expose long-range dependency failures and propose corrective inductive biases. ->read the paper
| Agents, Tools & Ecosystems | Work that builds environments, frameworks, or multi-agent systems for scalable, tool-using or science-oriented AI. | 🌟 GEM: A Gym for Agentic LLMs – provide an OpenAI-Gym-like simulator for agent environments, benchmarking RL algorithms and enabling reproducible training. ->read the paper 🌟 ToolUniverse: Democratizing AI Scientists – standardize tool discovery, creation, and orchestration to let any model become an autonomous scientific collaborator. ->read the paper ACON: Optimizing Context Compression for Long-Horizon LLM Agents – compress observation and dialogue histories into concise representations for efficient long-term interaction. ->read the paper The Unreasonable Effectiveness of Scaling Agents for Computer Use – show that structured rollout selection (bBoN) dramatically boosts reliability and near-human success in GUI automation. ->read the paper DataMind: Scaling Generalist Data-Analytic Agents – synthesize complex analytic tasks and train open-source agents that outperform proprietary baselines in multi-format data analysis. ->read the paper The Unreasonable Effectiveness of Scaling Agents for Computer Use – scale computer-use agents (CUAs) through Behavior Best-of-N selection, which converts long trajectories into concise behavior narratives and chooses the best among multiple rollouts, achieving near human-level performance across operating systems. ->read the paper
| Evaluation, Alignment & Governance | Papers that improve trust, detection, or alignment through new objectives, judges, or reward modeling. | Rethinking Reward Models for Multi-Domain Test-Time Scaling – compare step-wise and outcome-wise reward models across domains, finding generative outcome models most robust. ->read the paper Who’s Your Judge? On the Detectability of LLM-Generated Judgments – formalize judgment detection and build interpretable detectors to expose biases in LLM evaluators. ->read the paper
| That’s all for today. Thank you for reading! Please send this newsletter to your colleagues if it can help them enhance their understanding of AI and stay ahead of the curve. | How did you like it? | | |
|