Guide to Rapidly Improving AI Products Part 2
- Gregor Ojstersek and Hamel Husain from Engineering Leadership <gregorojstersek@substack.com>
- Hidden Recipient <hidden@emailshot.io>
Hey, Gregor here 👋 This is a paid edition of the Engineering Leadership newsletter. Every week, I share 2 articles → Wednesday’s paid edition and Sunday’s free edition, with a goal to make you a great engineering leader! Consider upgrading your account for the full experience here. Guide to Rapidly Improving AI Products Part 2Part 2 of the deep dive on evaluation methods, data-driven improvements and experimentation techniques from helping 30+ companies build AI products!
IntroCorrectly evaluating and continuously improving AI products is a really important topic. It’s what makes a difference between just a computer science experiment versus an actual useful AI product for the users. There are many unrealistic expectations, especially from company leaders and I’ve personally heard a lot of horror stories like:
Lucky for us, we have Hamel Husain with us once again for Part 2 of the Guide to Rapidly Improving AI Products. There are many highly relevant insights and we also go into fine details! Hamel is sharing a lot of useful insights from his personal experience, including how to properly conduct a roadmap to build AI products. Spoiler alert: A roadmap for building an AI product should look totally different than a roadmap for traditional Software Development! This is an article for paid subscribers, and here is the full index: - Sections 1 to 4 + 🎁 Introducing Hamel HusainHamel Husain is an experienced ML Engineer who has worked for companies such as GitHub, Airbnb, and Accenture, to name a few. Currently, he’s helping many people and companies to build high-quality AI products as an independent consultant.
Together with Shreya Shankar, they are teaching a popular course called AI Evals For Engineers & PMs. I highly recommend this course to build quality AI products as I have personally learned a lot from it. Check the course and use my code GREGOR35 for 1050$ off. The early bird discount ends this Friday. Sections 1 to 4 + 🎁Make sure to also read the first part, where we shared:
You can read the Part 1 here:
And now, we are diving deeper into populating your AI with synthetic data, how to maintain trust in evals, and how to structure your AI roadmap. Hamel, over to you! 5. Populate Your AI With Synthetic Data Is Effective Even With Zero UsersOne of the most common roadblocks I hear from teams is: “We can’t do proper evaluation because we don’t have enough real user data yet.” This creates a chicken-and-egg problem → you need data to improve your AI, but you need a decent AI to get users who generate that data.
Fortunately, there’s a solution that works surprisingly well: synthetic data. LLMs can generate realistic test cases that cover the range of scenarios your AI will encounter. Bryan Bischof, the former Head of AI at Hex, put it perfectly:
A Framework for Generating Realistic Test DataThe key to effective synthetic data is choosing the right dimensions to test. While these dimensions will vary based on your specific needs, I find it helpful to think about three broad categories:
These aren’t the only dimensions you might care about → you might also want to test different tones of voice, levels of technical sophistication, or even different locales and languages. The important thing is identifying dimensions that matter for your specific use case. For a real estate CRM AI assistant I worked on with Rechat, we defined these dimensions like this: But having these dimensions defined is only half the battle. The real challenge is ensuring your synthetic data actually triggers the scenarios you want to test. This requires two things:
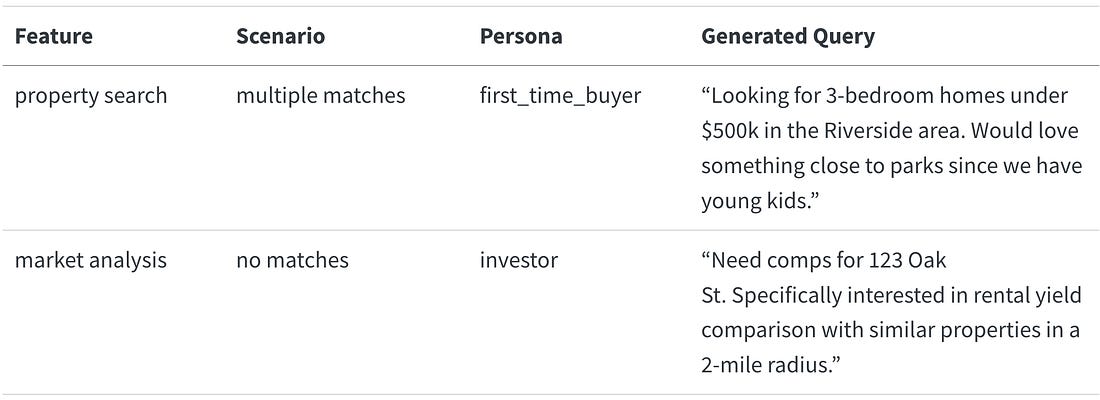
For Rechat, we maintained a test database of listings that we knew would trigger different edge cases. Some teams prefer to use an anonymized copy of production data, but either way, you need to ensure your test data has enough variety to exercise the scenarios you care about. Here’s an example of how we might use these dimensions with real data to generate test cases for the property search feature (this is just pseudo-code, and very illustrative): This produced realistic queries like:
The key to useful synthetic data is grounding it in real system constraints. For the real-estate AI assistant, this means:
We then feed these test cases through Lucy (Rechat’s AI assistant) and log the interactions. This gives us a rich dataset to analyze, showing exactly how the AI handles different situations with real system constraints. This approach helped us fix issues before they affected real users. Sometimes you don’t have access to a production database, especially for new products. In these cases, use LLMs to generate both test queries and the underlying test data. For a real estate AI assistant, this might mean creating synthetic property listings with realistic attributes → prices that match market ranges, valid addresses with real street names, and amenities appropriate for each property type. The key is grounding synthetic data in real-world constraints to make it useful for testing. The specifics of generating robust synthetic databases are beyond the scope of this article. Guidelines for Using Synthetic DataWhen generating synthetic data, follow these key principles to ensure it’s effective:
This approach isn’t just theoretical → it’s been proven in production across dozens of companies. What often starts as a stopgap measure becomes a permanent part of the evaluation infrastructure, even after real user data becomes available. Let’s look next at how to maintain trust in your evaluation system as you scale. 6. Maintaining Trust In Evals Is CriticalThis is a pattern I’ve seen repeatedly: Teams build evaluation systems, then gradually lose faith in them. Sometimes it’s because the metrics don’t align with what they observe in production. Other times, it’s because the evaluations become too complex to interpret. Either way, the result is the same → the team reverts to making decisions based on gut feeling and anecdotal feedback, undermining the entire purpose of having evaluations.
Maintaining trust in your evaluation system is just as important as building it in the first place. Here’s how the most successful teams approach this challenge: Understanding Criteria DriftOne of the most insidious problems in AI evaluation is “criteria drift” → a phenomenon where evaluation criteria evolve as you observe more model outputs. In their paper “Who Validates the Validators?”, Shankar et al. describe this phenomenon:
This creates a paradox: you can’t fully define your evaluation criteria until you’ve seen a wide range of outputs, but you need criteria to evaluate those outputs in the first place. In other words, it is impossible to completely determine evaluation criteria prior to human judging of LLM outputs. I’ve observed this firsthand when working with Phillip Carter at Honeycomb on their Query Assistant feature. As we evaluated the AI’s ability to generate database queries, Phillip noticed something interesting:
The process of reviewing AI outputs helped him articulate his own evaluation standards more clearly. This isn’t a sign of poor planning → it’s an inherent characteristic of working with AI systems that produce diverse and sometimes unexpected outputs. The teams that maintain trust in their evaluation systems embrace this reality rather than fighting it. They treat evaluation criteria as living documents that evolve alongside their understanding of the problem space. They also recognize that different stakeholders might have different (sometimes contradictory) criteria, and they work to reconcile these perspectives rather than imposing a single standard. Creating Trustworthy Evaluation SystemsSo how do you build evaluation systems that remain trustworthy despite criteria drift? Here are the approaches I’ve found most effective:... Subscribe to Engineering Leadership to unlock the rest.Become a paying subscriber of Engineering Leadership to get access to this post and other subscriber-only content. A subscription gets you:
|



Similar newsletters
There are other similar shared emails that you might be interested in: